NAFFT-Net Report
| 과목명 | 인공지능심화 |
|---|---|
| 교수 | 김원준 교수님 |
| 학과 | 전기전자공학부 |
| 학번 | 201910919 |
| 이름 | 이찬현 |
1. 요약
U-Net 구조를 Base Architecture로 삼았으며, NAFNet의 Basic Block을 이용하여 기본 모델의 틀을 구성하였고, 아래의 개선점들을 추가하며 모델을 완성하였다.
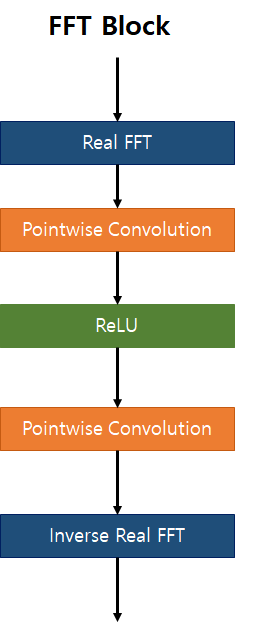
개선점 1; FFT Block 추가
- 영상신호처리 과목을 통해 Blur에는 Low-frequency 요소가 더 많음을 학습
- 하지만 CNN은 Feature의 Edge나 Contour와 같은 High-Frequency 성분을 추출하고 인식함
- 따라서 Low-Frequency Feature를 인식하여 학습이 가능하도록 Frequency Domain에서의 분석 Block (FFT Block)을 추가하여 Low ~ High Frequency 모두를 파악할 수 있도록 모델 설계
개선점 2; Channel Attention 개선
- 기존 NAFNet에서 Channel Attention을 간략화하는 과정에서 2개의 FC Layer 1개 생략
- 이떄 이왕 1개로 줄이는거 2개의 FC Layer 보다도 성능이 좋았던 ECA-Net의 1D Convolution 기반 Channel Attention을 차용함
개선점 3; FFT Loss의 사용
Spatial 영역의 L1Loss를 사용하며, 여기에 Frequency 영역에서 L1Loss를 구하는 FFT Loss를 추가하여 학습 진행
< 100epoch
- Spatial 영역의 L1Loss만 사용할때보다 더 빠르게 Blur를 제거해나감
100 ~ 600 epoch
- 학습이 진행되지않고 PSNR이 횡보하는 모습을 보임
- 아마 FFT Loss와 L1 Loss의 비율 문제로 학습이 어려워진것으로 판단
개선점 4; DO-Conv 사용
Encoding에 있어 Block 개수에 따른 Blur 복구 능력차이가 컸음
- 12개의 Encoding Block은 Blur가 심한 이미지를 아예 복구하지 못한 반면,
- 28개의 Encoding Block은 Blur가 심한 이미지도 복구해 나감을 확인
하지만 Block의 개수를 늘리는것은 더 많은 Computing power를 사용하기에 Convolution을 Depthwise-Overparameterized Convolution으로 교체하여 성능향상을 노림
- 더 많은 Parameter를 통해 다양한 Computing Vision 모델의 성능향상을 이끈 만큼, Deblurring에 있어서도 효과가 기대됨
2. Related Work
1-1. NAFNet
Nonliear Activation Free Network
: 기존 Image Restoration 모델들의 Activation function들과 복잡성을 낮추며, SOTA를 능가하는 성능을 나타낸 모델
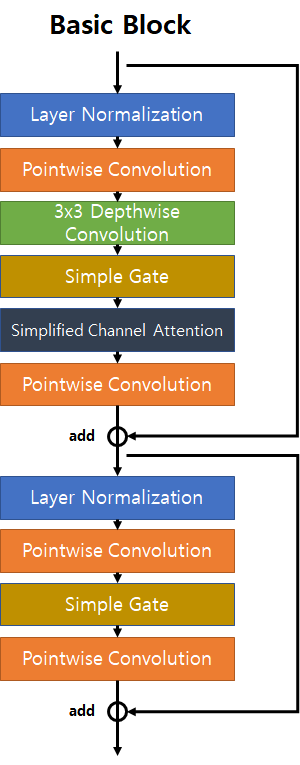
블록내의 Complexity를 낮추기 위해 다음과 같은 축약 작업을 진행
Convolution layer, ReLU, Shortcut으로 구성된 Baseline에서 다른 SOTA 방식을 추가/교체하며 성능향상 연구
GELU와 Channel Attention을 가볍게 만듦
Gated Linear Units (GLU)에서 Activation fucntion(
)가 없어도, Element-wise multiplication을 통해 비선형성을 만들 수 있음 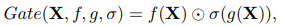
GELU는 GLU꼴로 표현가능하기때문에, GELU를 Simple gate로 제작
Simple gate: Feature를 Channel dimension으로 이등분하여, 서로 Element-wise multiplication
Channel Attention의 형태또한 GLU꼴로 표현가능하므로, Simple Channel Attention 형태로 제작
Simple Channel Attention:
는 MLP를 의미하며, 를 생략하여도 비선형성이 보장되기에 제거함 학습 성능 향상을 위한 Layer Normalization의 사용
Image 크기 때문에 Mini-batch가 작아지며, Batch normalization의 Statistics를 이용하기 어려움
이때, Visual 분야에서 Transformer가 등장하며, Layer Normalization이 성능향상 기법으로 사용되는것을 발견
따라서 Deblurring 작업에서도 Layer Normalization을 통해 성능향상을 이뤄내고자 사용
실제로 10배 높은 Learning rate에서도 안정된 학습을 도출
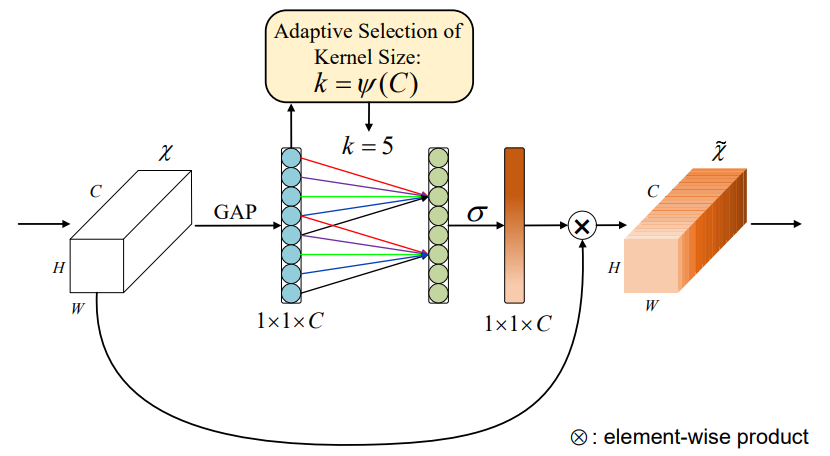
1-2. ECA-Net
Efficient Channel Attention for Deep Convolutional Neural Networks
기존 Channel Attention의 연산성능을 개선함과 동시에 Dimension Reduction을 피하는 방법에 대한 모델
연산량 감소와 Channel Reduction을 피하기위해 1D Convolution 이용
- SEBlock의 Channel Attention에서의 FC Layer 2개를 Dimension Reduction없이 1D Convolution으로 교체
- 이때 정보의 Coverage를 위해 Kernel 크기가 중요한데 논문에서는 Channel dimension에 Adaptive 하도록 설정하여, 성능 손실없이 모델 간소화 성공
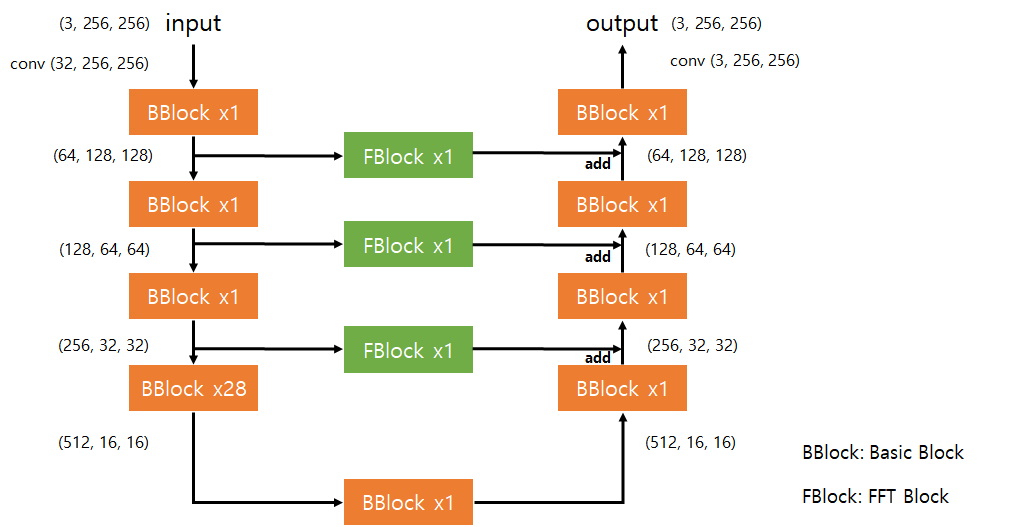
3. Model Architecture
3-1. Basic Block
3-2. FFT Block
3-3. NAFFT Model
- Encoding: BBlock과 Conv2d(kernel=2, stride=2)를 통해 image 크기 감소
- Decoding: PixelShuffle을 이용하여 image 크기 증가
4. 결과
Blur - Predict - Ground Truth 순서

5. 고찰
다음의 몇가지 아쉬움이 남는 과제
아쉬움 1; 다양한 Test를 해보지 못한 아쉬움
일반적으로 1 epoch에 1시간이 걸렸으나, 논문들을 참고하였을때 1000 ~ 3000 epoch 필요
따라서 다양한 환경에서의 테스트 결과를 확인할 수 없었던것이 과제에 가장 큰 아쉬움으로 남음
하지만 몇가지 작은 성과는 얻을 수 있었음
- L1Loss와 FFTLoss를 동시에 사용할 때 비율에 따라서, 학습이 진행되지 않거나, 이미지가 오히려 변형되는 문제를 확인함으로서, Loss를 여러개 사용할때는 세심한 조절이 필요하다는 것을 배움
- Encoding block의 개수가 많아질수록 강한 Blur를 제거해나가는것을 확인할 수 있었고, Convolution의 Parameter 증가를 통해 어느정도 Block을 대체하여 강한 Blur에서도 인식하게 함을 확인할 수 있었음
- FFT Block을 사용했을때와 사용하지 않았을때 초반 Epoch 구간에서 FFTBlock이 있는 쪽이 좀 더 Edge가 뚜렷함을 경험적으로 확인할 수 있었음
아쉬움2; FFT Block에 대한 아쉬움
- Skip Connection에 FFT Block을 연결할때, 잔차를 추가적으로 연결하지 못한 점
- U-Net의 Skip connection 부분이 아닌, NAF Block에 삽입해보지 못한 점
- Input image에 아예 FFT Image를 Concat해보지 못한 점
'Computer Vision' 카테고리의 다른 글
| DeepRFTNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
|---|---|
| NAFNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
| MobileNetV3 쉬운 논문 리뷰 및 Pytorch 구현 (0) | 2022.08.02 |
| MnasNet 쉬운 논문 리뷰 (0) | 2022.08.01 |
| ShuffleNet 쉬운 논문 리뷰/구현 (0) | 2022.07.20 |




댓글