MobileNetV3 & NetAdapt
[Reference]
논문 링크: Searching for MobileNetV3
github: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/README.md
- 2019년 5월 (Arxiv)
- Google Inc.
- Andrew Howard, Mark Sandler, Grace Chu et al.
blog: https://soobarkbar.tistory.com/62
[TODOS]
- 중의적 표현을 자제하여 작성
- 어려운 표현들은 좀 더 풀어쓰기
[Question]
요약
MobileNetV3는 Mobile Phone CPU에 최적화
- NetAdapt Algorithm과 NAS(Network Architecture Search)를 조합하여 새로운 구조 제안
MobileNetV3는 Large, Small model로 나뉨
- Large: High Resource / Small: Low Resource
Object Detection과 Semantic segmantation에 적용시켜 테스트
- Semantic semantation의 경우, 효과적인 Segmentation decoder인 LR-ASPP(Lite Reduced Atrous Spatial Pyramid Pooling) 제안
MobileNetV3는 성능면에서 몇가지 향상을 이뤄냄
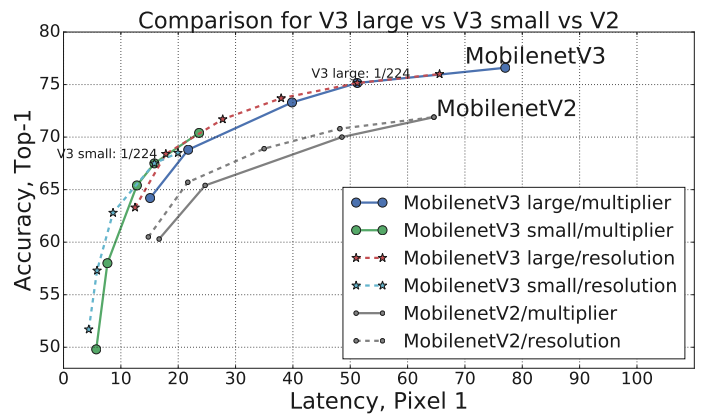
- MobileNetV3-Large는 MobileNetV2에 비해 ImageNet classification에서 3.2% 정확하면서도 20%의 latency가 개선됨
- MobileNetV3-Small은 MobileNetV2에 비해 비슷한 latency로 6.6% 더 정확했음
- MobileNetV3-Large는 MobileNetV2에 비해 MS COCO detection에서 25% 빠르면서도 비슷한 정확도를 보였음
- MobileNetV3-Large LR-ASPP는 MobileNetV2 R-ASPP에 비해 Cityspace segmentation에서 34% 빠르면서도 비슷한 정확도를 보였음
용어 정리
swish: ReLU를 대체하기 위한 함수. sigmoid에 ReLU를 곱한 꼴 =
NetAdapt Algorithm: Layer의 Optimization을 진행하는 NAS의 일종
NAS(Network Architecture Search): RNN기반의 Controller를 이용하여 Network의 구성요소들을 통해 모델을 샘플링하고, Accuracy가 좋은모델에 Reward를 주어 Reinforcement Learning 방식으로, Accuracy가 뛰어난 모델을 자동생산
Platform-Aware NAS: 대상 플랫폼에 최적화하는 NAS / 대상 플랫폼에서 Inference를 진행하였을때, Latency가 작은쪽으로 모델을 구성하는 네트워크 / 자세한 설명은 링크 참조
LP-ASPP: Spatial Pyramid Pooling을 진행할 때 좀 더 넓은 Receptive field를 위해 Atrous Convolution 연산을 진행하게 한 것
- Spatial Pyramid Pooling:
Pareto Optimal: 어느한쪽도 양보할 수 없는 최적의 타협상태 (양보하면 전체의 손해 증가)
Knowledge distillation: 미리 잘 학습된 큰 네트워크(Teacher network)의 정보를 작은 네트워크(Student network)에게 전달하는 것
Search Space: 네트워크 탐색 범위, 즉 네트워크를 구성하는 구성요소들을 고르
Networks
SqueezeNet: SENetwork에서 제시된 개념으로써, Excitation Network를 통해 채널별 중요도를 추출하기전, 각 채널의 대표값들을 Squeeze(Global Average Pooling)하는 Network 자세한 설명은 링크 참고
MobileNetV1: Depthwise Separable Convolution을 사용하여, 기존 Convolution 연산에 비해 향상된 연산 효율을 보임 자세한 설명은 링크의 1번 항목 참고
MobileNetV2: Inverted Residual 구조와, Linear Bottleneck 구조로 연산량 감소 및 정보손실 방지 자세한 설명은 링크의 2, 3번 항목 참고
- Inverted Residual: Input과 Output Channel은 Compact하게 표현하며, 내부적으로는 Channel의 수를 증가시켜 비선형 변형의 표현력 감소를 막음
CondenseNet: 각 Group마다 중요한 Input만을 추려서 Group Convolution을 진행
ShiftNet: 값 비싼 Spatial Convolution을 대체하기 위해, Point-wise Convolution이 포함된 Shift Operation을 제시
SEBlock: Squeeze, Excitation 연산을 통해 특징을 잘 갖고있는 채널들에게 가중치를 부여하는 Self-attention Block 자세한 설명은 링크 참고
설명
1. Introduce
- Mobile applications에서 딥러닝 추론이 가능해지며, 배터리 수명 향상, 더 빠르고 효율적인 모델 개발의 필요성이 대두됨
- 이를 위해, MobileNetV3는 아래의 필수요소를 개발
- Complementary search techniques: 상호 보완적인 Network 탐색 방식
- New efficient versions of nonlinearities practical for the mobile setting: 모바일 환경에 효율적인 비선형 함수
- New efficient network design: 효율적인 Network 구성
- New efficient segmentation decoder: 효율적인 Segmentation 디코더의 구성
2. Related Work
2-1. Deep Neural Architecture
- SqueezeNet: 1x1 pointwise convolution를 Squeeze Network를 통해 MAdds(연산량)를 줄임
- MobileNetV1: Depthwise Separable Convolution을 통해 기존 Standard Convolution보다 뛰어난 연산효율을 보여줌
- MobileNetV2: Inverted Residual과 Linear bottleneck을 이용한 resource 효율 증가 및 정보 손실 방지
- CondenseNet: 각 Group마다 중요한 Input만을 추려서 Group Convolution을 진행
- ShiftNet: Spatial Convolution을 대체하기 위해, Point-wise Convolution이 포함된 Shift Operation을 제시
2-2. Automation architecture design Process
MnasNet에 대한 이야기와 동일 (추가적인 내용은 다음의 링크를 참고)
Architecture Design 과정의 자동화를 위해 Reinforcement learning 방식이 처음으로 제시됨 (= AutoML 방식)
큰 Search Space는 너무 크고 복잡하여 초기의 Architecture search는 간단한 Cell을 제작하는 정도로 이루어졌고, 제작된 Cell이 모든 Layer에서 사용됨
- 이 방식은 다양성이 보장되지 못함
- 다양하지 못하므로, 성능이 좋은 Architecture가 발견되기 어려움
최근에(2019) Block-level의 Search space를 가지고, 다양한 Operation들과 Connection들로 구성된 Block들에서 단계적인 Search가 가능하게 함
이때 Search의 Computational cost를 줄이기 위해 미분가능한 Search Framework들(Proxylessnas, DARTS, Fbnet)이 gradient-based(경사하강법) optimization과 함께 사용됨
기존의 Network를 Mobile Platform에 적용시키는것에 중점을 두고, 보다 효율적인 Automated Network 간소화 알고리즘을 개발하였음
- Mobile Platform에 적용하기 위해 Accuracy말고도, Latency도 모델제작에 고려함
2-3. Quantization
- Quantization(양자화)는 Reduced Precision Arithmetic(정밀 산술 감소)를 통해 네트워크 효율성을 향상시킬 수 있음
- FP32 → INT8 연산으로 양자화시켜, 연산 속도 향상
2-4. Knowledge distillation
- Knowledge distillation(학습 전이)를 통해 작은 Network의 정확성을 큰 Network를 통해 보완함
3. Efficient Mobile Building Blocks
Mobile model들은 보다 더 효율적인 블록들을 탑재해왔음
3-1. MobileNetV1, MobileNetV2
3-2. MnasNet
간략하게 말하자면 Mobile에 최적화된 Model을 샘플링(도출)하는 Network인데,
이를 통해 Latency와 Accuracy를 모두 챙긴 Network인 MnasNet-A1을 발견
- MnasNet-A1: MobileNetV2의 SEBlock가 들어있는 BottleNeck Layer 들과 3x3 또는 5x5 Convolution Operation layer들로 구성되어있음
이때, SEBlock이 ResNet에서 병합된 위치와 다른곳에서 병합됨
- Inverted Residual 구조에서 Pointwise Convolution을 통해 Expansion이 진행되고 난 다음에 SEBlock을 붙임
이를 통해 큰 표현력을 가지고 있을때 Attention을 진행
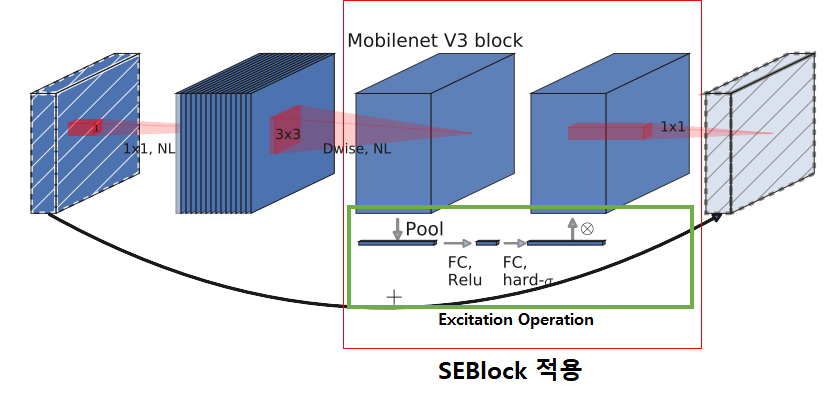
3-3. MobileNetV3
MobileNetV3는 위의 3-1, 3-2 에서의 블록들을 조합하여 보다 효율적인 모델을 제시
Non-linearity를 변형된 swish (h-swish)함수로 업그레이드
Squeeze, Excitation Operation에서 뿐만아니라 Swish 함수에서도 모두 Sigmoid를 이용하는데,
이는 계산이 비효율적이며, 고정소수점 연산에서 정확성을 유지하기 어렵기때문에, 이를 Hard Sigmoid로 교체하여 사용함
4. Network Search
Network Search는 Network를 최적화하고, 발견하는데 있어, 굉장히 powerful한 툴
- Platform-aware(플랫폼 인식) NAS를 이용해, 각 Network block들을 최적화함으로써, Global network structures(전체 네트워크 구조들)를 탐색
- 이후 NetApdapt Algorithm를 사용하여 Layer별 Filter의 개수를 탐색
- 위 두 방식은 상호 보완으로 작동하며, Hardware platform(일반적으로 Mobile 환경)에 최적화된 모델들을 효과적으로 찾을때 유용
4-1. Platform-Aware NAS (= MnasNet) for Block-wise Search
Platform-Aware NAS: MnasNet (자세한 내용은 링크 참고)
- Platform-Aware Neural Architecture Search (= MnasNet)를 사용하여 Global Network Structure(전체 네트워크 구조)를 탐색함
4-1-1. Reward Method
Latency와 Accuracy의 타협점을 찾기위해 생성된 모델에 점수(reward)를 매기는 방식
목표 Latency(TARGET)에 기반한 각 모델 m에 대해
모델 지연시간 LAT(m), 모델의 정확도 ACC(m)의 최적의 타협점(Pareto optimal)에 근사하기 위해 다음과 같은 Reward 함수를 사용
- Reward =
- Reward =
4-1-2. Large Mobile Models
- MnasNet-A1과 동일하게 RNN-based Controller를 사용하고, 동일하게 Factorized Hierarchy(분해된 계층적) Search Space를 사용하기 때문에
- 80ms의 Latency를 목표로 한 Large Mobile Models와 비슷한 결과를 보임
- 따라서 Large Mobile Models의 경우는 단순히 MnasNet-A1와 똑같이 초기화를 진행하고, NetAdapt 및 기타 Optimizations들을 적용시킴
4-1-3. Small Mobile Models
Original reward 의 Parameter
는 Small Mobile Models에 맞지 않음을 발견 - NetAdapt 과정에서 Latency를 줄이려했는데, Accuracy가 날뜀
- Small Model의 경우, Model의 Latency(지연시간)에 따라 Accuracy(정확도)가 극적으로 변하는 것을 관찰함
따라서 Latency에 따라 민감하게 반응하는 Accuracy를 보상(Compensation)하기 위해 가중치를 더 작은 음수 값으로 변경
기존 MnasNet에서
이었던 것을, 로 변경 - Hard Constraint가 되며 제약 시간 범위 이내에선 Accuracy에 집중하여 모델 샘플링 (제약 시간내에서 목표하는 Accuracy에 더 가까운 모델 추출)
- 반면 Latency가 커짐에 따라 reward가 많이 감소하여, Model이 Penalty를 피하기위해 Search하지 않음 (= 좁은 Latency Range를 가짐)
새로운 가중치
와, 초기 Seed Model을 탐색하기위해 처음부터(from scratch) 새로운 아키텍쳐 탐색을 시작한 뒤, NetAdapt 및 기타 Optimization을 통해 최종적으로 MobileNetV3-Small 모델을 얻음
4-2. NetAdapt for Layer-wise Search
Quantization 등의 Optimization을 진행해주는 NAS의 일종
- Latency를 줄이는 방향으로 학습 진행
- Filter를 제거하고, weight를 최적화하며 Optimization 진행
4-2-1. NetAdapt 논문
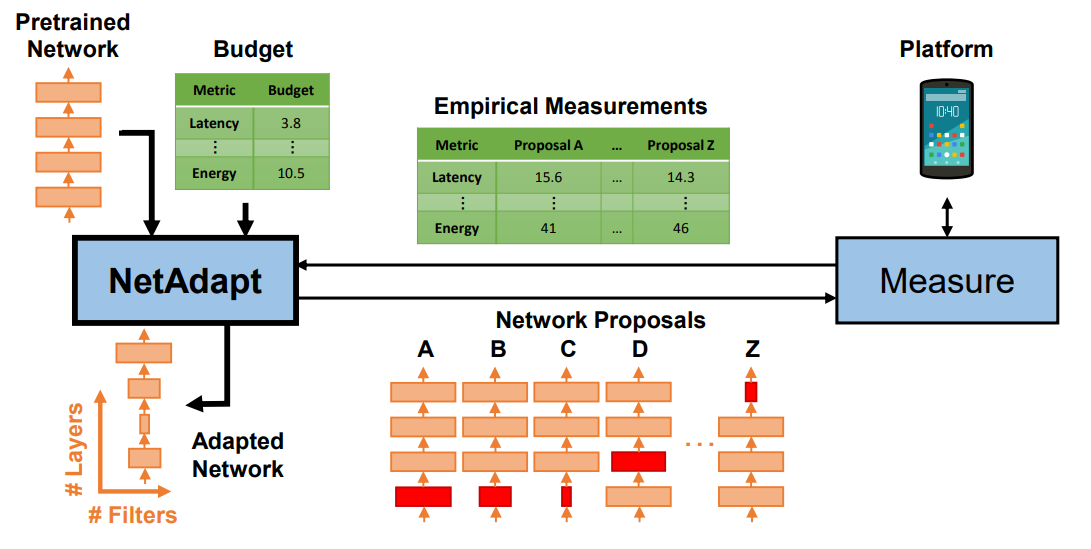
- MnasNet과 같은 Platform-Aware NAS에 의해 발견된 한 Pretrained Network Architecture에서 시작 (ex. MnasNet-A1 구조)
- MnasNet과 같은 Platform-Aware NAS에서 Seed Network Architecture는 다음과 같이 추출됨
- Res: 현재 Latency
- Bud: 목표하는 Latency
- Con: 제약 조건

line 3: 제작된 Network가 목표 Latency 밑으로 올때까지 반복
line 4: 제약 조건, 현재 Latency보다 작게 만드는 조건
line 5-8: Network안에 있는 K개 Layer 마다 다음의 동작 수행
line 6: 제거할 filter 개수 설정- Latency 조건에 맞는 개수를 탐색해 나감
line 7: 제거할 filter 설정- L2-norm Mangnitude가 작은 순서로 Filter 제거
line 8: Short-term fine tuning 진행- Fine tuning은 오래걸리는 작업이므로, Network 탐색과정에선 간단한 Short-term Fine tuning (short iteration)만 진행
- 이 과정을 통해 Accuracy가 추락하지 않게 방지함
line 9: 여태까지 제작했던 Network 중에서 가장 Accuracy가 높은 Network를 선택하여 다음단계 Input으로 물림
line 11: 최종적으로 산출된 목표 Latency 미만의 Latency를 가지는 모델 중 Accuracy가 높은 모델에 대해 Long-term fine tuning 진행
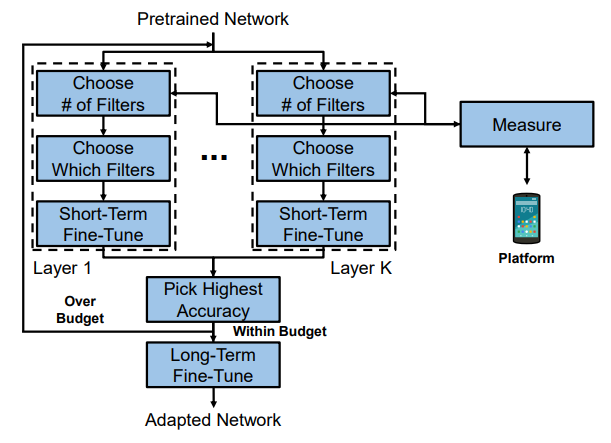
4-2-2. NetAdapt at MobileNetV3
4-2-1 항목과 유사한 설명
Expansion Layer의 크기와 bottleneck들을 줄여나가며, Accuracy를 보장하는 선에서 Latency를 최소화 하도록 학습하는 NAS
- Expansion Layer의 개수 감소와 Bottleneck을 줄인채로 여기서 filter의 수나, weight들을 조절하며 Latency 최적화
제안들: Expansion Layer의 크기 감소 / Bottleneck 감소
새로운 Proposals(제안들)의 집합을 생성
- 각 Proposal은 Architecture의 변경을 Representation 함
- 이때의 Architecture는 이전스텝과 비교하여, 못해도
만큼의 Latency 감소를 나타냄 - 논문에선
각 Proposal에 대해 이전 단계에서 Pre-trained 된 모델에 새롭게 제안된 Architecture를 붙이고, 누락된 가중치를 적절히 자르거나(Truncate) 랜덤하게 초기화 함
- 단계 T에 대한 각 Proposal을 미세조정하여 Accuracy에 대한 대략적인(Coarse) 추정치를 얻음
- 논문에서
, 즉 10000개의 단계동안 Expansion Layer의 크기와 Bottleneck 수를 조절해가며 Network 탐색
Some Metric(논문에선 정확도의 변화정도를 줄이도록)으로 평가하여, 최고의 Proposal을 선택함
목표 지연시간에 도달할때까지 이전의 단계들을 반복
NetAdapt에서 Metric은 정확도 변화를 최소화 하는 것
논문에선 이 알고리즘을 수정하여 Latency 변화와 Accuracy 변화 사이의 비율을 최소화하는 방향으로 NetAdapt Step을 진행
이 비율들은 각 NetAdapt 단계들에서 생성된 모든 Proposals에 대한 것이므로, 아래의 식을 최대화 하며 제약조건을 만족하는 것을 하나 선택함
- Latency는 많이 변했고, Accuracy는 적게변한 모델 선택
이 직관은 Proposal들이 이산적(Bottleneck의 개수 변경 등)이기 때문에, Trade-off 곡선의 기울기를 최대화 하는 Proposals를 선호함
목표가 도달할때까지 반복하며, 반복할때마다 새로운 Architecture를 훈련
NetAdapt에서 사용된 것과 동일한 Proposal 생성기를 MobileNetV2에서 사용
5. Network Improvements
네트워크 탐색외에도 추가 개선을 위해 다음의 노력을 함
- 네트워크의 시작과 끝에서 Computational cost가 크기때문에, 현재의 Search Space 외부의 요소로 Layer들을 다시 설계
- Swish non-linearity의 업그레이드 버전인 h-swish(hard swish)를 도입하며, Quantization에 친화적이고 더 빠른 계산을 제공
5-1. Redesigning Expensive Layers
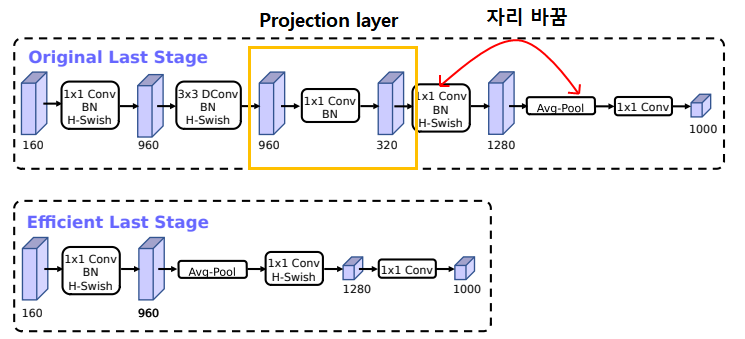
5-1-1. Layer Reducing
Network 최종단의 몇개의 Layers들에서 Final Features를 생성할 때, 좀 더 효율적으로 작동하게 함
현재는 MobileNetV2의 Inverted bottleneck구조뒤에 1x1 Pointwise Convolution 연산을 통해 Features를 많이 뽑는 구조
- Expansion은 더 많은 Feature들을 뽑기위해 중요하지만, Latency Cost가 너무 큼
Cost를 줄이기위해, Average pooling 이후에 Expansion을 진행하게 함
이를 통해 Latency에서 자유로워짐
위의 과정을 통해 Feature 추출 layer가 뒤로가게되며, 앞단에 있던 Bottleneck projection layer (960→320 1x1 Conv)가 필요하지 않게 됨
- Channel expansion을 하자마자, 바로 Avg Pooling과 1x1 Convolution을 통해서 고차원의 Feature를 추출하게 변경
이 과정들을 통해 정확도 손실 없이, 30Million의 연산량 감소 및 Latency 7ms(기존 11%) 감소
5-1-2. Filter Reducing
현재 Mobile model들은 Edge Detection을 위한 3x3 Full Convolution Layer에서 32개의 filters 사용
종종 이런 filter들은 서로의 대칭 이미지일 때도 있음
따라서 이 filter를 줄이고 새로운 Nonlinearities (h-swish)를 추가하여 중복 제거
- 기존 ReLU 또는 swish와 함께 32개의 Filter들을 사용한것에서
- h-swish와 함께 16개의 Filter를 사용하도록하여 10M 연산량 감소 및 2ms의 Latency 감소
5-2. Nonlinearities
- swish와 같은 비선형 함수는 성능은 좋으나, Floating point 연산을 진행하기에 임베디드환경에 부적함
- 따라서 이를 대체하기 위한 새로운 함수(h-swish)를 구상
5-2-1. Sigmoid를 Hard analog 함수로 대체
- 사용자 정의 Clip함수가 아닌, ReLU6를 통해 최댓값 제한
5-2-2. Hard swish
- ReLU6의 사용을 통해 기존에 ReLU6를 위해 제작된 연산최적화 기능을 이용할 수 있으며
- Hard하기 때문에 Quantize를 진행할때, 정밀도 손실이 적게 발생
- 또한 단편적인 함수로 구성되어있기에 메모리 액세스 횟수 감소로도 이어짐
5-2-3. Nonlinearity의 Cost와 Network 깊이와의 관계
신경망이 깊어질수록 Resolution이 떨어지며 자연스레 메모리 사용량 감소
또한 swish의 이점은 깊은 층부터 효과적임을 발견
따라서 h-swish를 깊은층부터 적용시킴 (후반부 부터)
- 그래도 여전히 Latency Cost는 존재
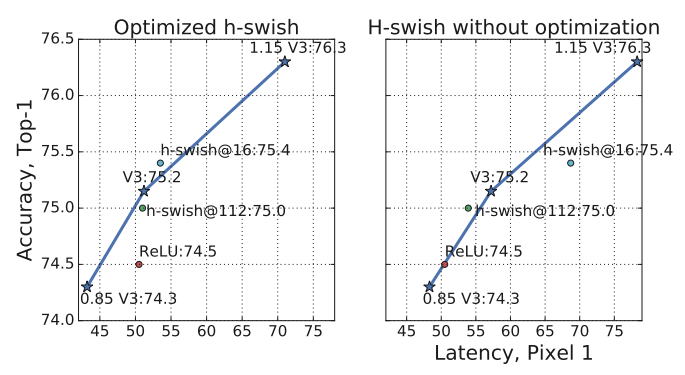
5-2-4. 결과
- h-swish 함수만으로 Accuracy 향상 가능
- 약간의 Latency cost 발생
5-3. Large Squeeze-and-Excitate
- MnasNet에서 Squeeze와 Excite Bottleneck의 크기는 Convolutional bottleneck와 연관있었음
- 하지만 여기선, Expansion Layer 수의 1/4로 고정
- 이를 통해 Parameter는 증가했으나, 정확도 향상 및 Latency는 유지할 수 있었음
6. Experiments
6-1. Classification
ImageNet Dataset 사용
6-1-1. Training setup
RMSProp optimizer / momentum = 0.9
Initial Learning rate = 0.1
- 3 epochs 마다 0.01 decay
batch size = 4096 (128 images per chip / 4x4 TPU Pod 사용)
Dropout = 0.8
L2 weight decay 1e-5
Inception 논문과 동일한 Image Processing을 거침
Batch-normalization layers, average decay = 0.99
6-1-2. Measurement setup
Google Pixel Phone이용
TFLite Benchmark tool 이용
- Single threaded large core 이용하여 Latency time 측정
- Multi-core는 측정하지 않음
6-2. Results
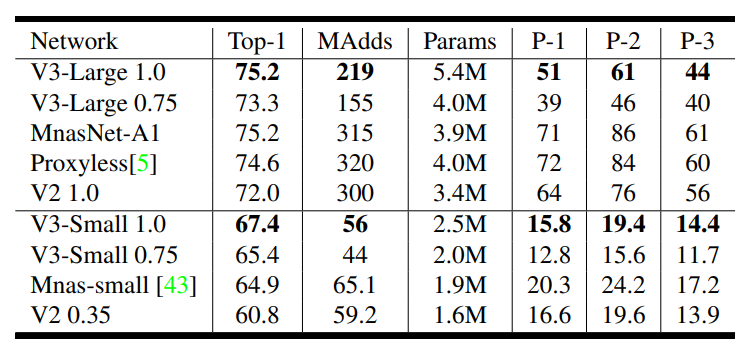
Floating point Performance
P-1~3: Pixel 1/2/3에서의 Latency
Quantized 된 성능
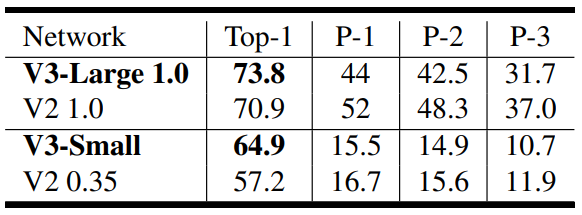
각각의 Component들이 결과(Accuracy / Latency)에 미치는 영향
위쪽(높은 Accuracy) 또는 왼쪽(Latency 감소) 방향으로 이동함
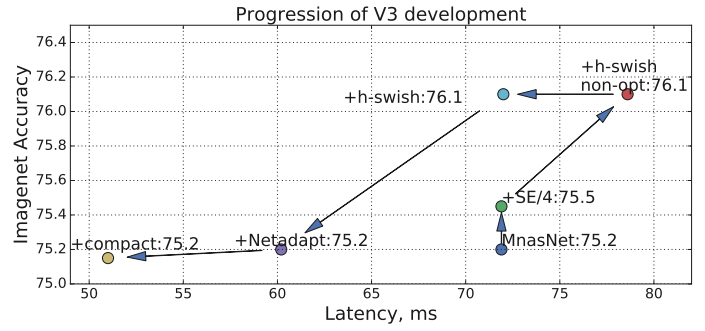
6-2. Detection
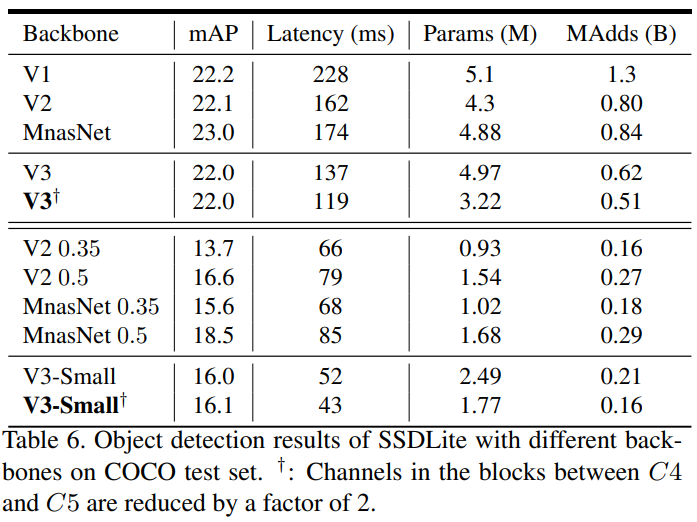
- MobileNetV3를 SSDLite의 Feature Extractor로 사용하여 측정
- COCO Dataset을 이용
6-2-1. MobileNetV2의 경우
MobileNetV2의 마지막 Feature Extractor Layer중 출력 Stride가 16인 부분에 SSDLite의 첫번째 Layer연결
- Detection literature의 표현을 따라, 이를 C4로 명명
MobileNetV2의 마지막 Feature Extractor Layer중 출력 Stride가 32인 부분에 SSDLite의 두번째 Layer연결
- Detection literature의 표현을 따라, 이를 C5로 명명
6-2-2. MobileNetV3의 경우
C4
- V3-large에서 13번째 Bottleneck block의 Expansion layer
- V3-small에서 9번째 Bottleneck block의 Expansion layer
C5
- large, small에서 모두 Pooling 직전의 Layer
이때 C4, C5의 채널 개수를 factor(
) 만큼 감소시켜서 COCO Detection의 연산 Cost를 감소 시킴 - 이는 MobileNetV3는 1000개의 Classes를 분류하기 위한것이라
- 90개를 Detection하는 COCO dataset에서는 일부 Channel들만 맞춰져 있을 것임
- 따라서 중복(Redundant)을 제거해주어 추론
6-2-3.Results
MobileNetV2, MnasNet보다 mAP가 월등하거나 Latency가 작게 나옴
6-3. Semantic Segmentation
Backbone으로 MobileNetV2와 V3를 사용할 예정
새로운 Segmentation head; LR-ASPP 사용
- LR-ASPP = Lite Atrous Spatial Pyramid Pooling
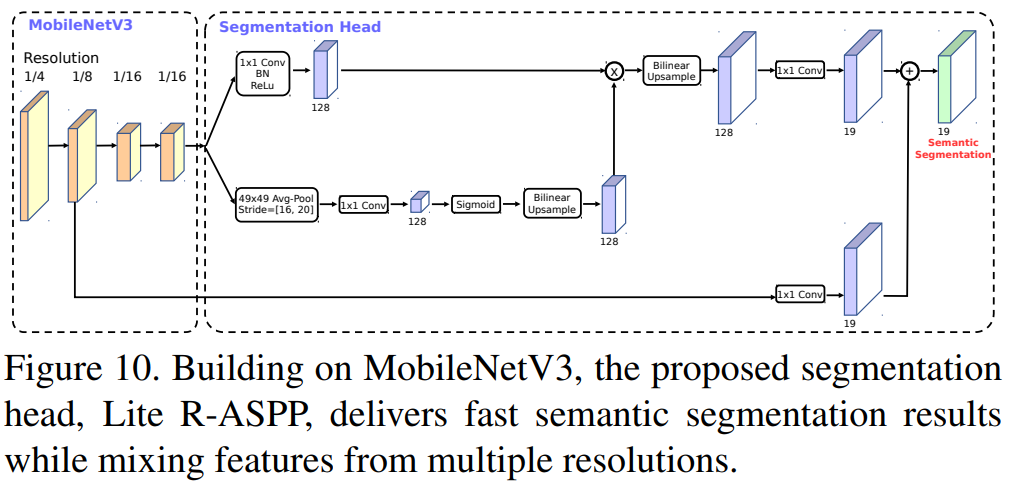
6-3-1. LR-ASPP
- Squeeze-and-Excitation 모듈과 유사한 방식으로 Global-Average Pooling을 사용함
- 이 Module에서 큰 Stride와 하나의 1x1 Convolution만을 사용하여 일부 계산을 절약
- 우리는 Atrous Convolution를 MobileNetV3의 마지막 Block에 붙여, Denser feature를 추출
- 디테일한 Information을 얻기위해, Skip connection 추가함
6-3-2. Training
Pre-train 없이 ImageNet으로 처음부터 학습되며, Single-scale Input으로 Evaluate함
6-2 Detection에서와 동일하게, backbone network의 마지막 channels를 Factor(
) 만큼 reduce - Cityspace Semantic Segmentation은 19개의 Classes가 있고,
- ImageNet은 1000개의 Classes를 학습시키기 때문에, 마지막 Feature중에서 일부만 Mapping 되어있거나, 중복되어있을 것이기 때문
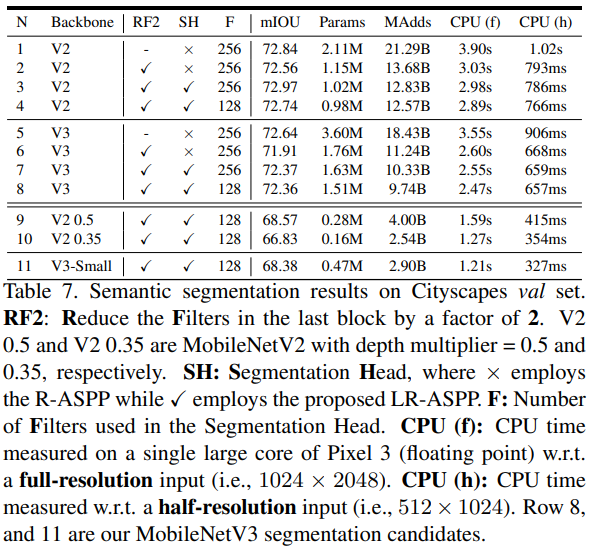
6-3-3. Results
RF2: 마지막 Channel을 2배 줄였는지 안줄였는지
SH: Segmentation Head로 R-ASPP를 썼는지, LR-ASPP를 썼는지
CPU: Pixel3에서의 추론 시간
- f: Full resolution (
) - h: Half resolution (
)
- mIOU와, 추론시간 모두 V2보다 V3를 Backbone으로 썼을 때 좋음
- Segmentation Head로 LR-ASPP를 사용하였을때, 추론시간와 mIOU모두 상승
- 또한 RF2를 진행했을때, 감소하는 mIOU보다 의미있는 추론시간 감소(기존의 26% 감소)를 보임
구현
[Code Reference]
https://github.com/d-li14/mobilenetv3.pytorch/blob/master/mobilenetv3.py
1. 코드 개요
- SEBlock과, MobileNetV2 구성방식 참고하였음
2. 코드
자세한 설명은 주석 참고
2-1. MobileNetV3.py
import torch.nn as nn
import math
__all__ = ['mobilenetv3_large', 'mobilenetv3_small']
# Channel 수를 항상 8로 나누어 떨어지게 만들어주는 함수
def _make_divisible(x, divisible_by=8):
import numpy as np
return int(np.ceil(x*1./divisible_by)*divisible_by)
def _make_divisible(value, divisor, min_value=None):
"""
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
모든 레이어의 채널 개수가 8로 나누어 떨어질 수 있게 함
"""
if min_value is None:
min_value = divisor
# 322 / 8 = 320
new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
# 나누어 떨이지게 할 때, 값이 일정수준 밑으로 내려가는일은 없게 보정
if new_value < 0.9 * value:
new_value += divisor
return new_value
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x+3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.h_sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.h_sigmoid(x)
class SEBlock(nn.Module):
def __init__(self, in_channels, r=4): # 논문에선, Reduction Ratio를 4로 고정
super(SEBlock, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.excitation = nn.Sequential(
nn.Linear(in_channels, _make_divisible(in_channels // r, 8)),
nn.ReLU(inplace=True),
nn.Linear(_make_divisible(in_channels // r, 8), in_channels),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.squeeze(x) # Global Average Pooling
y = y.view(b, c) # Batch size 축은 놔두고, 나머지를 일렬로 펴서 FC Layer에 입력
y = self.excitation(y)
y = y.view(b, c, 1, 1)
return x * y # MnasNet-A1의 구조를 따름
def conv_3x3_bn(in_channels, out_channels, stride):
return nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=1,
bias=False
),
nn.BatchNorm2d(out_channels),
h_swish()
)
def conv_1x1_bn(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=False),
nn.BatchNorm2d(out_channels),
h_swish()
)
# Block의 모양은 본문의 3-2항목 참고
# 또는 https://ech97.tistory.com/entry/mnasnet의 2-2 항목 참고
class InvertedResidual(nn.Module):
def __init__(self, in_channels, hidden_dim, out_channels, kernel_size, stride, use_se, use_hs):
super(InvertedResidual, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and in_channels == out_channels
# 확장하지 않는 경우
if in_channels == hidden_dim:
self.conv = nn.Sequential(
# Depth-wise Convolution
nn.Conv2d(
hidden_dim,
hidden_dim,
kernel_size,
stride,
padding=(kernel_size - 1) // 2,
groups=hidden_dim,
bias=False
),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True), # Network의 후반부에만 h_swish 사용
nn.Conv2d( # 1x1 convolution
hidden_dim,
out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=False
),
nn.BatchNorm2d(out_channels)
)
# 확장하는 경우 // 본문의 3-2 항목
else:
self.conv = nn.Sequential(
# Point-wise Convolution // 채널 확장
nn.Conv2d(
in_channels,
hidden_dim,
kernel_size=1,
stride=1,
padding=0,
bias=False
),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Depth-wise Convolution
nn.Conv2d(
hidden_dim,
hidden_dim,
kernel_size=kernel_size,
stride=stride,
padding=(kernel_size - 1) // 2,
groups=hidden_dim,
bias=False
),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excitation // Self-attention
SEBlock(hidden_dim) if use_se else nn.Identity(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Point-wise Linear // 채널 축소
nn.Conv2d(
hidden_dim,
out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=False
),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
if self.identity:
return x + self.conv(x) # Skip-connection
else:
return self.conv(x)
class MobileNetV3(nn.Module):
def __init__(self, cfgs, mode, num_classes=1000, width_mult=1.):
super(MobileNetV3, self).__init__()
self.cfgs = cfgs
assert mode in ['large', 'small']
# Building first layer
in_channels = _make_divisible(16*width_mult, 8)
layers = [conv_3x3_bn(3, in_channels, 2)]
# Building Inverted residual blocks
block = InvertedResidual
for k, t, c, use_se, use_hs, s in self.cfgs:
out_channels = _make_divisible(c * width_mult, 8)
hidden_dim = _make_divisible(in_channels * t, 8)
layers.append(block(in_channels, hidden_dim, out_channels, k, s, use_se, use_hs))
in_channels = out_channels
self.features = nn.Sequential(*layers)
# Building last layers
# in_channels은 위의 for문의 마지막과 이어짐
self.conv = conv_1x1_bn(in_channels, hidden_dim)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
final_channels = {'large': 1280, 'small': 1024}
final_channels = _make_divisible(final_channels[mode] * width_mult, 8) if width_mult > 1.0 else final_channels[mode]
self.classifier = nn.Sequential(
nn.Linear(hidden_dim, final_channels),
h_swish(),
nn.Dropout(0.2),
nn.Linear(final_channels, num_classes)
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def mobilenetv3_large(**kwargs):
cfgs = [
# k, t, c, SE, HS, s
[3, 1, 16, 0, 0, 1],
[3, 4, 24, 0, 0, 2],
[3, 3, 24, 0, 0, 1],
[5, 3, 40, 1, 0, 2],
[5, 3, 40, 1, 0, 1],
[5, 3, 40, 1, 0, 1],
[3, 6, 80, 0, 1, 2],
[3, 2.5, 80, 0, 1, 1],
[3, 2.3, 80, 0, 1, 1],
[3, 2.3, 80, 0, 1, 1],
[3, 6, 112, 1, 1, 1],
[3, 6, 112, 1, 1, 1],
[5, 6, 160, 1, 1, 2],
[5, 6, 160, 1, 1, 1],
[5, 6, 160, 1, 1, 1]
]
return MobileNetV3(cfgs, mode='large', **kwargs)
def mobilenetv3_small(**kwargs):
cfgs = [
# k, t, c, SE, HS, s
[3, 1, 16, 1, 0, 2],
[3, 4.5, 24, 0, 0, 2],
[3, 3.67, 24, 0, 0, 1],
[5, 4, 40, 1, 1, 2],
[5, 6, 40, 1, 1, 1],
[5, 6, 40, 1, 1, 1],
[5, 3, 48, 1, 1, 1],
[5, 3, 48, 1, 1, 1],
[5, 6, 96, 1, 1, 2],
[5, 6, 96, 1, 1, 1],
[5, 6, 96, 1, 1, 1]
]
return MobileNetV3(cfgs, mode='small', **kwargs)
if __name__ == "__main__":
model = mobilenetv3_small()
from torchsummary import summary
summary(model, (3, 224, 224))
'Computer Vision' 카테고리의 다른 글
| DeepRFTNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
|---|---|
| NAFNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
| MnasNet 쉬운 논문 리뷰 (0) | 2022.08.01 |
| ShuffleNet 쉬운 논문 리뷰/구현 (0) | 2022.07.20 |
| Squeeze-Excitation Network 쉬운 논문 리뷰/구현 (0) | 2022.07.19 |




댓글