DeepRFT
[Reference]
논문 링크: Deep Residual Fourier Transformation for Single Image Deblurring
Github:
- 2021년 11월(Arxiv)
- Xintian Mao, Yiming Liu, Wei Shen, Qingli Li, Yan Wang
목차
Abstract
기존 ResBlock을 이용한 Deblurring 작업은 고주파 정보에 있어선 잘 Capture하지만 저주파에선 부족한 부분을 보여왔음
- 또한 ResBlock은 Deblurring하는데 있어 중요한, long-distance 정보를 잘 파악하지 못하는 문제가 있음
따라서
저주파~고주파,단거리~장거리정보를 모두 Capture할 수 있는 Res FFT-Conv Block을 제시- 기존 MIMO-Unet에 Res FFT-Conv Block을 적용할시 PSNR: +1.09dB (+33.23dB) 성능향상을 이룸
Introduction
1. 기존 Kernel/CNN 방식의 문제점
Deblur가 발생하는 요인은 다음과 같음
- 불규칙한 카메라/물체의 움직임
- 광학적인 문제; 초점이 맞지 않음
하지만 Kernel / CNN 방식의 model은 이러한 문제를 제대로 바라보지못함
- 움직임보다는 noise에 민감한 방식이기 때문에
- 실제 Deblurring Scenario에는 적합하지 못한 경우가 많음
- CNN의 Receptive-field가 제한적이므로 Global한 정보를 담는데 실패함
흐릿한 이미지에 비해 날카로운 이미지는 훨씬 적은 저주파 및 더 많은 고주파 정보를 가지고 있음
하지만 Convolutional Neuron Network의 아래와 같은 성질때문에 저주파 정보를 모델링하는데 있어 표현력이 부족하다고 판단
- Lower-layer: 이미지의 Edge나 Contour를 Capture하는 경향이 있고, (고주파 성분)
- Higher-layer: Lower-layer에서의 특성을 결합하는 특징이 있음
2. 해결방안
따라서 우리는 Global한 정보(Information; Context)를 파악하기위해 주파수에 주목해야함
이미지 전반의 정보를 가지고있는 FFT 특성을 이용
- FFT에 Point-wise Convolution를 결합하여,
- 이미지 전반의 수용 필드와, 저주파 성분에 집중할 수 있게 함
추가적으로 우리는 Convolution 연산을 Depthwise Over-parameterized Convolution (DO-Conv)로 교체
- 추가적인 power 사용없이 뛰어난 Convolution을 보여줄수있는 Convolution Network 제작
Related work
1. Deep Image Deblurring
Transformer-based 구조(ex. SwinIR)는 Global Context Modeling 능력을 보여줌
- 하지만 Complexity가 너무 큼
2. End to End Deblur Model with ResBlock
DeepDeblur Network 이후로,
Conv-ReLU-Conv구조를 기반으로 ResBlock을 설계하는게 기본이 되었음
이후 ResBlock을 개선하기 위한 다양한 테크닉들이 등장
- SAPHN: Content-aware 구조 사용
- MRPNet: Channel-attention Block
- HINet: HIN Block
- SDWNet: Dilated-Convolution 사용
하지만, 제시된 모델들은 모두 Spatial 영역에만 초점을 맞추고, Frequency 영역의 중요한 정보를 Capture하지 못함
3. Applications of Fourier Transform
최근에는 주파수영역에서 정보를 추출하는 몇가지 방법이 제시되고 있음
아래의 FFT Model의 성공 사례에 영감을 받아 본 논문에서도 Res FFT-Conv Block을 제안
- FDA: Image segmentation에서 이미지 style 변경으로인한 영향을 완화하기위해 저주파 정보를 swap함
GFNet: Image classification에서 Long-term spatial dependencies를 학습함
- LaMa: Inpainting*를 위해 FFT 사용
SDWNet: Wavelet transform을 적용
4. Depthwise Over-parameterized Convolutional Layer
논문: DO-Conv을 참고하여 작성하였음.
- 기존 Convolution에 학습가능한 Parameter를 추가
Only linear layer만 추가하는것은 Over-parameterization만 되기에 고려되지않으며, 이와같은 구조가 보다 적은 Parameter를 가지는 Linear layer로 표현될 수 있는 경우에는 더욱 비선호됨
하지만 Over-Parameter가 표현력을 늘리지는 못해도, 훈련을 가속화하는 수단으로는 경험적으로 입증됨
- 또한 DO-Conv 논문에서는 훈련 가속 뿐만아니라, 성능 또한 증가할 수 있음을 나타냄
[보충 필요]
용어 정리
- Dilated-Convolution: Kernel에 0을 interploation해서 좀 더 넓은 Receptive-field를 갖게한 방식
- Inpainting: 이미지의 손상/열화로 발생한 유실부분을 채우는 작업
- Depthwise Over-parameterized Convolutional Layer (DO-Conv): 링크 참고
설명
1. ResBlock
2개의 3x3 Convolution Layer와, ReLU Activation function을 사용함
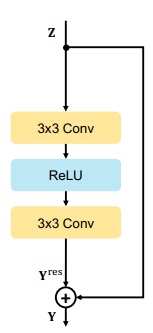
ResBlock을 쌓음으로, 더 큰 Receptive Field를 확보할 수 있으며, 빠르게 수렴할 수 있음
- 하지만 Receptive Field를 위해 Block을 Deep하게 쌓으면 연산량의 문제가 발생함
Convolution의 경우는 Edge와 같은 고주파 정보를 주로 학습하여, 흐림(저주파)정보를 수집하는 능력이 부족
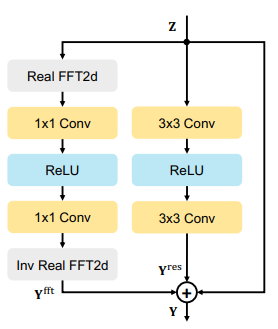
2. Residual Fast Fourier Transform Block
주파수 영역의 Global Context를 파악할 수 있도록 FFT Block 추가
- Blur image와 Sharp image의 고주파와 저주파의 불일치를 모델링 할 수 있으며
- Long-Short 상호작용을 모두 포착할 수 있음 (넓은 Receptive field를 부여하기 때문)
2-1. DFT
2-1-1. 1D DFT
특정 신호를 기본 주파수의 선형결합으로 표현함
- 따라서 어떤 주파수건 Global한 Context를 가지고있따고 볼 수 있음
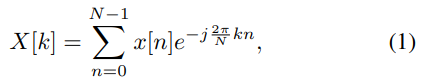
2-1-2. 2D DFT
2D Signal에 순차적으로 행과, 열에 대해 1D DFT를 진행한 것
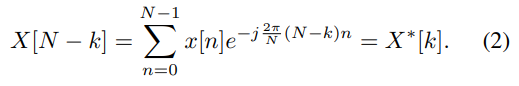
이 또한 Symmetric한 성질을 갖고있기때문에, 우반면는 좌반면의 정보를 통해 구할 수 있음
- FFT는 대칭성을 이용해서 효율적으로 DFT를 진행하는 방법
2-1-3. FFT Block
입력 이미지를
라 하자
- H: 높이 / W: 너비 / C: 채널
- FFT Block은 다음과 같은 과정으로 처리됨
- 2D 실수(real; 좌반면)에 대한 FFT 진행:
- 생성된 결과의 실수(real)파트와 허수(imaginary)파트를 채널방향으로 Concatenation진행:
에서 두개를 채널방향으로 Concat 했으므로,
Point-wise convolution 2개와 ReLU 진행
이때, 모든 주파수들이 동일한 1x1 Kernel을 공유하며, 모든 주파수간의 정보와 상관관계를 모델링 할 수 있음**
- 해당 결과를 Inverse FFT 진행하여 Spacial domain으로 원복:
- 최종적으로 일반 Res Block와 FFT Block의 결과를 더하여 출력
3. Deep Residual Fourier Transform Framework
효율적인 다중스케일 이미지 디블러링을 위한 MIMO-UNet을 기반으로 설계
- MIMO-UNet의 모든 ResBlock을 Res FFT-Conv Block으로 대체
- Deblurring 능력을 향상시키기위해 1x1 Conv를 제외한 모든 Conv Layer를 DO-Conv로 교체
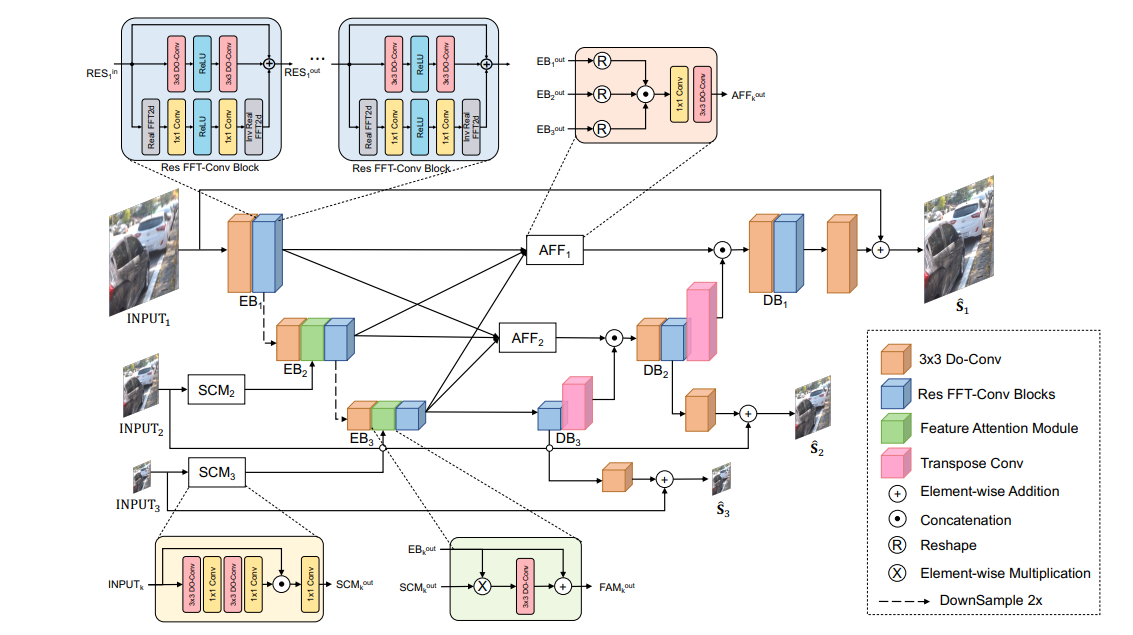
3-1. Depthwise over-parameterized convolution (DO-Conv)
DO-Conv는 Image classification / Semantic segmentation / Object Detection에서 훌륭한 잠재력을 보여줌
- 더 많은 매개 변수 (Over Parameters)를 통해 훈련을 가속화하고
- Depthwise Convolution으로 Convolution layer를 보강하여 더 좋은 성능을 달성함
- 본 논문에선 Image deblurring에서도 DO-Conv를 추가하여 더 낮은 Loss에 수렴하는데 도움이 되는 것을 보여줌
- DO-Conv는 추론단계에서 두개의 인접한 선형 연산을 통해 Convolutional Conv로 결합(대체)될 수 있기에 Pointwise Conv를 제외한 모든 Conv를 DO-Conv로 교체
3-2. Loss Function
3가지의 Loss를 사용하여 평가
- k번째 Predicted 영상
- k번째 Ground Truth sharp 영상
- 상수
최종
이며, 는 경험적으로 0.05와 0.01로 설정
- Multi-Scale Charbonnier (MSC) loss
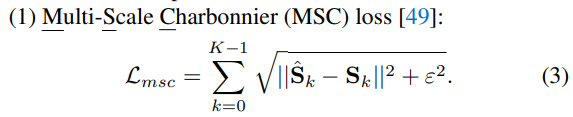
- Multi-Scale Edge (MSED) loss
는 Laplacian Operator
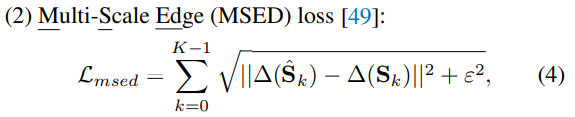
Multi-Scale Frequency Reconstruction loss
주파수 영역에서 Predicted 영상과 Ground truth sharp 영상의 차이를 평가
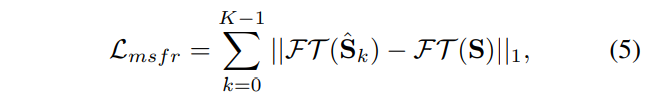
실험
1. 실험 환경
MRPNet의 학습 전략을 따라감
image_size: 256x256
batch_size: 16
training_epoch
- MIMO-UNet: 3,000
- Otherwise: 1,000
loss_function
- MIMO-UNet: MSC + MSED + MSFT
- Otherwise: Charbonnier loss + Edge loss
위의 Loss에서 Multi scale만 빠짐optimizer: Adam
learning_rate:
→ (Using cosine annealing strategy) augmentation: Random horizontal / vertical flip, Crop
- Crop method: SDWNet의 방식을 따라, Sliding window 방식으로 256x256 이미지로 Crop
2. Res FFT-Conv Block 평가
2-1. PSNR
- MRPNet의 2개의 Backbone network인 U-Net과 ORSNet에서의 평가
- MRPNet-small (기존보다 3배 적은 Channel)에서 평가
- MIMO-UNet 에서의 평가
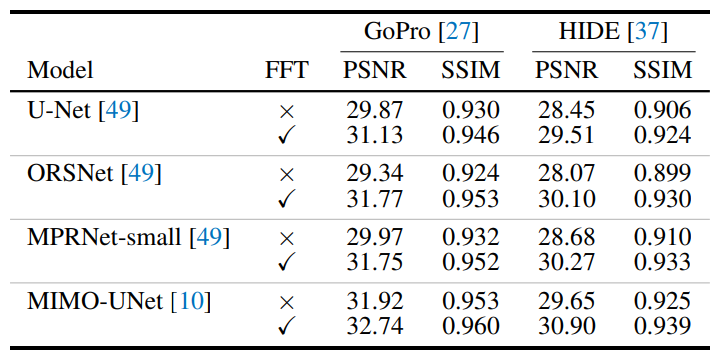
FFT Block을 사용하였을때, 최대 PSNR +2.43 dB의 성능향상을 나타냄
2-2. Low-frequency capture
- (a): Basic ResBlock만 사용하였을때, Freq domain에서 확인한 주파수 캡쳐
- (b): Res FFT-Conv Block을 통해 학습한 FFT Block과 Res Block의 결과

FFT Block을 결합하였을때, ResBlock 또한 저주파 Capture 성능이 올라가있는것을 확인할 수 있음
2-3. Ablation study
- Res FFT-Conv Block을 Fast Fourier Convolution으로 대체하였을땐 PSNR Drop 현상 발생
- 또한 Basic Res보다 DeepRFT에서 loss가 더 빨리 수렴함을 확인
'Computer Vision' 카테고리의 다른 글
| NAFFT-Net 구현 (인공지능심화 과제) (0) | 2022.12.05 |
|---|---|
| NAFNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
| MobileNetV3 쉬운 논문 리뷰 및 Pytorch 구현 (0) | 2022.08.02 |
| MnasNet 쉬운 논문 리뷰 (0) | 2022.08.01 |
| ShuffleNet 쉬운 논문 리뷰/구현 (0) | 2022.07.20 |




댓글