NAFNet
[Reference]
논문 링크: Simple Baselines for Image Restoration
Github: https://github.com/megvii-research/NAFNet
- 2022년 4월(Arxiv)
- Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, Jian Sun
목차
Abstract
Nonlinear Activation Free Network
기존 Image Restoration 모델들의 복잡성을 낮추며, SOTA를 능가하는 성능을 나타내는 모델
- non-linear activation 제거: Sigmoid, ReLU, GELU, Softmax
- 2022/04 기준 SOTA보델의 8.4%의 Computational power로 PSNR 0.38dB 개선
Introduction
Inter-block (블록 간) Complexity를 낮추기 위해 single-stage U-Net 채택
Intra-block (블록 내) Complexity를 낮추기 위해
- 기본적인 구성요소인 Convolution Layer, ReLU Activation, Shortcut 만 남겨놓고 SOTA의 방식을 추가/교체하며 성능향상 연구
- GELU는 GLU의 특수한 경우로 간주될 수 있음
- CA는 GLU와 유사성을 밝혀, CA의 non-linear activation fucntion (Sigmoid, ReLU, GELU)도 제거할 수 있음
Related work
기존 Intra-block Complexity의 요소들
- Spatial-wise가 아닌 Channel-wise attention map을 이용하여 Self-attention의 계산 비용을 줄임
- GLU와 Depth-wise convolution가 Feed-forward network 구조로 채택
- Window-based multi-head self-attention
- 지역정보 파악능력 향상을 위한 Depth-wise conv를 추가한 Locally-enhanced feed-forward network
Gated Linear Units (GLU)
기존 NLP(Natural Language Processing) 부터 최근 Computer Vision까지 GLU는 우수성을 보여옴
이 논문에서는 GLU의 성능을 저하시키지 않으며, GLU의 Non-linear activation function을 제거
- Non-linear activation function을 제거한 GLU는 자체적으로 Non-linearity를 가진다는 사실에 기초하여
- Non-linear activation function을 그냥 두 가지 Feature map의 곱으로 대체함
용어 정리
MACs: Multiplications ACcumulate; 연산량
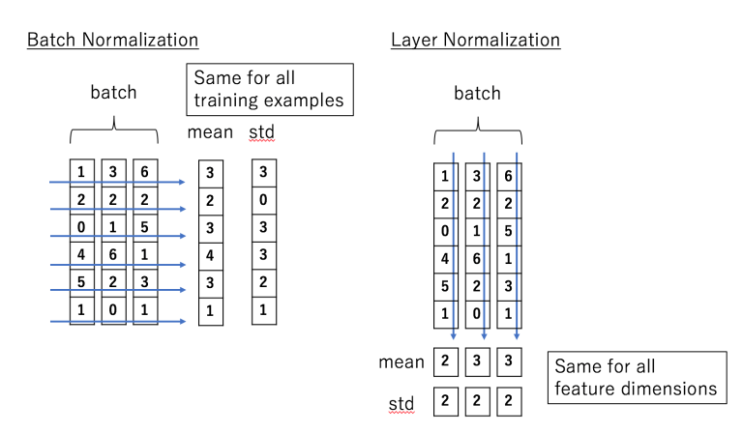
Layer Normalization: Batch Normalization과 유사
Batch 방향으로 Mean과 Std를 구해서 정규화 하는 것이 아니라
Layer 방향; Feature 방향으로 Mean과 Std를 구해서 정규화 함
- 따라서 Feature간 의존성이 없고, 훈련 프로세스를 안정하게 만들어줘서 Learning Rate의 증가를 가능하게 함
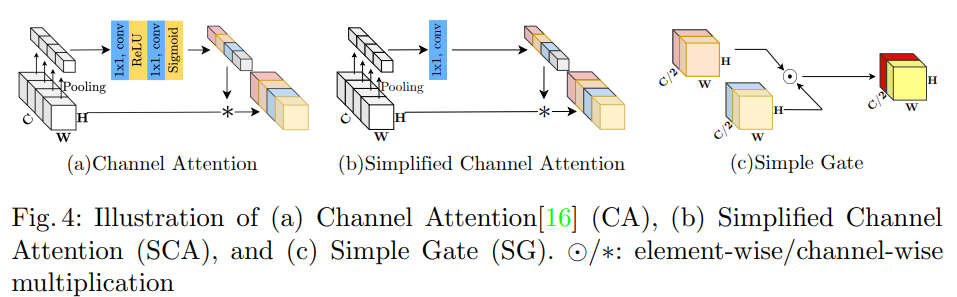
Channel Attention Module (CA): 본문 CA 참고
Gated Linear Unit (GLU): 본문 GLU 참고
Gaussian Error Linear Unit (GELU):
참고 Blog: https://hongl.tistory.com/236
각각의 parameter에 1 또는 0을 곱해서 특정 조건의 parameter만 뽑아주는 gating이 되는 ReLU와 Dropout같은게 필요함
이때 ReLU는 param의 부호만 보고 판단하고, Dropout은 Stochastic하게 gating함
이 두개를 합쳐, 값에 의해 Stochastic하게 곱하게 한게 GELU
따라서 (표준편차에 따라) 다른 입력에 비해 얼마나 큰지에 대한 비율로 gating이 진행되며 아래의 두개의 효과를 얻음
- 확률적인 해석 가능
- 미분가능한 함수 형태
설명
1. Build A Simple Baseline
- 최대한 심플하게 제작하고자, 필요한것만 추가한다는 개념을 가지고 접근
- HINet Simple에 이어 16 GMACs의 연산량 (256x256의 입력 기준)
2. Architecture
- (b): PlainNet
- (c): PlainNet with LayerNorm, CA(Channel-wise Attention) / ReLU -> GELU
- (d): Nonlinearity Activation Free Model; GELU와 CA를 SCA(Simplified Channel Attention)와 SimplieGate로 병합
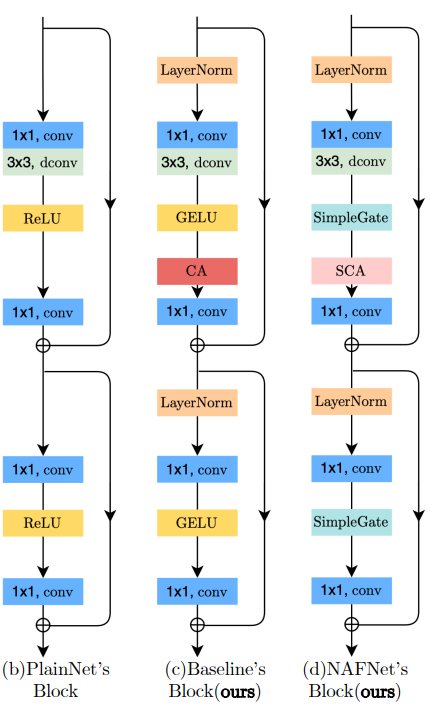
2-1. Architecture
블록간 Complexity를 줄이기위해 Single-stage U-shaped architecture with skip-connections를 적용
2-2. A Plain Block
최대한 단순하게 가기 위해 PlainNet: Conv, ReLU, Skip connection의 요소만 있는 Network부터 시작
Transformer 구조 대신 Convolution을 사용하는 이유
- Transformer구조가 Computer vision에서 의미있는 결과를 만들지만, 일부 연구에선 Transformer가 SOTA를 위해 필요하지 않을 수 있음
- Depth-wise convolution은 Self-attention보다 훨씬 간단함
- 이 논문은 Transformer과 Convolution의 장단점을 논의하기 위한것이 아닌, Baseline(몇몇 nonlinearity를 제거해도 괜찮다는)을 제시해주기 위한 논문이기 때문
2-3. Normalization
모든 Computer vision에서는 정규화 작업이 중요하게 사용됨
본 논문에서는 Plain block위에 Layer Normalization을 얹음
Instance normalization
- 작은 Batch 크기로 인해 Batch normalization을 포기해서 불안정한 statistics가 발생하는것을 Instance Normalization을 통해 작은 Batch 크기의 문제를 방지함
- 하지만 이를 적용했을때 항상 성능이 향상되는것은 아니므로, Manual하게 조정하는작업이 필요함
Layer normalization
Transformer구조의 발전에 따라 Layer normalization은 많이 사용되게 됨
이에 Image Restoration 작업에서의 SOTA를 위해서는 Layer normalization이 중요할 수도 있겠다는 hint를 얻음
Learning rate를 10배 증가하더라도 훈련을 원활하게 할 수 있을 것임
- 학습 속도가 클 수록 성능이 크게 향상 됨
따라서 훈련 프로세스를 안정화할 수 있기에, Plain block에 Layer Normalization을 얹음
2-4. Activation
- ReLU는 많이 사용되고있지만, GELU로 많이 대체되는 추세
- 해당 모델(NAFNet)에서도 GELU로의 교체가 Deblurring 작업에서의 이득(+0.21dB)을 가져오므로 교체
2-5. Attention
Computer Vision에서 Transformer구조가 유행하며, Attention 구조에도 많은 관심이 생기는 추세
Vanilla self-attention은 모든 특징들의 선형결합으로 대상 특징을 생성하여, 특징 사이의 유사성에의해 가중치가 부여됨
따라서 Global정보를 포함할 수 있게함
복잡성 증가
- Image restoration에서는 고해상도 작업도 있기때문에, 높은 복잡성은 큰 문제
따라서 Fix-sized local window에서의 Self-attention를 적용시켜 Global 정보는 부족하지만, 복잡성을 낮춤
- 본 논문에서는 Depth-wise Convolution에서 Local 정보가 잘 포착되기때문에, Fix-sized local window 방식을 이용하지 않음
이들과 달리, Spatial-wise attention을 Channel-wise attention으로 변환하면, Global 정보량은 획득하되, Complexity가 줄어듦
- Channel-wise는 이미 Image restoration task에서 입증된바 있으므로 본 논문에서도 사용
2-6. Summary
기존의 Non-linear Activation Function을 제거하여 모델 구성
Block의 최종적인 구성
- Layer Normalization: lr으로부터 오는 훈련 프로세스의 불안정을 낮춤
- Depth-wise Convolution: 지역정보 수집에 있어 fixed-sized local window 방식의 attention을 대체할 수 있음
- GELU: 본 모델의 부족한 성능을 ReLU를 GELU로 교체함으로서 보강
- Channel Attention (CA): Spatial-Attention과 비교하여 Global 정보는 챙기며, Computational power는 낮음
구조
앞서 설명한 Baseline을 가지고, 단순성을 유지하며 성능을 향상시키기위해 SOTA method를 연구하였고, GLU10이 적합함을 찾음
1. GLU
GLU는
와 같은 선형변환과 (sigmoid)와 같은 비선형변환으로 이루어져있으며, 이들의 Element-wise multiplication (이 또한 비선형성 제작) 으로 이뤄져있음
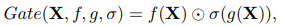
- 이를 Block 구조에 추가하면, 성능향상은 보장하지만, 블록 내 연산량 증가 또한 발생할 것
- 이를 해결하기 위해 Block에 있는 GELU에 대해 다시 생각해보자
2. GELU
정규분포의 누적분포함수를
라 할 때, GELU는 다음과 같이 표현되며, 근사화 됨
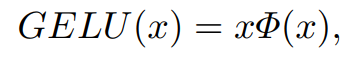
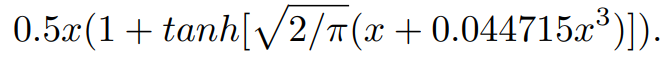
식 1에 의해 GELU는 GLU의 특정 경우임을 알 수 있음
는 identity function 이며, 를 로 만듦 이를 통해, GLU가 Activation function의 일종으로 간주되어, Activation function을 대체할 수 있을 것으로 추측됨
GLU자체가 비선형성(
, Multiplication between feature)을 포함하고 있고, 이에 에 의존하지 않음을 알 수 있음 가 제거되더라도, Element-wise multiplication이 있어 비선형성을 가짐
이 사실들을 바탕으로 GLU를 변형하여 GELU의 비선형성을 대체
Feature map을 Channel dimension에서 2개의 파트로 나누고
(c) Simple Gate라고 표기해놓은 부분과 같이, 두 파트를 Element-wise로 곱함
이를 통해 Deblurring 작업에서 PSNR +0.41dB의 성능 향상 달성
- GLU가 GELU를 대체할 수 있음을 확인
- 이제는 블록에 남아있는 비선형함수 (Sigmoid, ReLU)를 단순화 시킬 차례
3. Simplified Channel Attention
CA의 구조는 기존의 Attention과 비교해, Global 정보를 캡쳐하며 효율적인 계산을 가지고있음
(a) Channel Attention은 다음과 같은 과정을 가짐
공간 정보를 채널별(Channel first)로 Squeeze(Global Average Pooling; 채널의 정보를 모두 담고 있음) 한 뒤,
Multi Layer Perceptual (MLP; point-wise conv)를 적용하여, Channel attention을 계산하여
이를 Feature map에 가중치를 부여하는데 사용
식으로 나타내면 다음과 같음
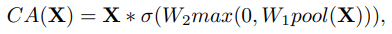
는 fully-connected layer (MLP 이지만, 사실상 point-wise conv와 동일한 작업을 수행함) - ReLU는
사이에 존재하며, 는 이들의 연산 이후에 적용됨 - 이 값을 Feature map
와 Channel-wise product ( ) 진행
CA를 함수로 간주하고 식을 변형하면 다음과 같음
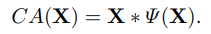
식 1과 유사해지며 GELU와 같이 GLU의 특정한 경우로 생각할 수 있게 되었음
이제 중요한 파트 (Global 정보, Channel 정보)를 남겨놓은채 GLU와 같이 Simplification을 진행
- GLU 형식의 경우 Feature의 곱이 Non-linear하므로, sigmoid를 생략할 수 있으며,
- 이것만으로도 비선형성이 확보되기에 추가적인 Activation function (여기선 ReLU)와 MLP (FC Layer 혹은 Point-wise conv)를 제거해도 됨
최종적으로 CA를 다음과 같은 식 (Simplified Channel Attention)으로 축약함
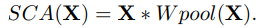
더 단순해졌지만, Deblurring 작업에서 PSNR +0.09dB의 성능 향상을 가져옴
실험
1. Ablantions; 절제
Adam optimizer (
, weight decay = 0)
- Cosine annealing schedule에 따라 200K의 iteration동안 Learning rate 1e-3에서 1e-6으로 감소하며 모델 훈련
Image size = 256x256
Batch size = 32
default width = 32; Computation budget에 따라 조정
number of blocks = 36
훈련의 안정성을 위해 skip-init을 적용 / MPRNet-local에 이어 TLC를 채택하여 Training by patches와 Testing by full images로 부터 발생하는 성능 저하를 개선함
1-1. PlainNet 부터 simple baseline 까지
PlainNet의 Training이 Default 설정으로는 불안정했기에 다음과 같은 수정을 함
- Learning rate를 10배로 줄이거나
- Layer Normalization을 도입하여, 학습 속도를 1e-4에서 1e-3으로 늘릴 수 있게함
1-2. Simple Baseline에서 NAFNet으로
기존 Baseline의 GELU와 Channel Attention을 GLU로 보고, 이를 단순화하여 NAFNet (Non-linear Activation Free) 으로 제작
- 낮아진 연산부담에 반해 PSNR +0.11dB의 성능향상 발생
1-3. Number of Blocks
블록의 수에 따라 발생하는 지연시간과 성능차이를 고려
기존 9개에서 36개로 블록 수를 늘렸을 때
- 성능은 크게 향상하였으나
- 지연시간은 크게 증가하지않음 (+14.5%)
36개에서 72개로 늘렸을 때
- 성능의 향상은 거의 없으나
- 지연시간은 크게 증가함 (+30.0%)
따라서 가장 잘 절충된 블록 수인 36으로 설정하고 실험
1-4. Simple Gate의
GLU에서의
를 가지고있으나, Feature간 곱셈에서 발생하는 비선형성으로 인해, 를 생략할 수 있는 원리를 이용
- GELU를 GLU로 근사화한 뒤, GLU와 같이, GELU에 있는 비선형성을 제거하기위해
- Channel dimension으로 행렬을 나눠서 Element-wise multiplication을 진행하는 Simple Gate 구조로 제작하여 GELU를 대체함
2. Applications
- Width: 32 → 64
- Batch size: 64k
- Epoch: 400K
- Augmentation: Random Crop
2-1. Deblurring
SOTA의 methods를 채택하여, Augmentation으로 Flip과 Rotate가 추가됨
- 이를 통해 직전 SOTA (MPRNet-local)를 PSNR +0.38dB를 능가함

결론
- SOTA에서의 필수 구성 요소를 추출하여 PlainNet에 적용
- 이때 Non-linear Activation Function은 교체되거나 제거하여 더욱 단순화 시킬 수 있음을 알 수 있음
- 이를 이용하여 Non-linear Activation Free인 NAFNet을 제안하여
- SOTA를 달성하는데 있어 Non-linear Activation Function이 필요할 수 없다는 것을 입증함
'Computer Vision' 카테고리의 다른 글
| NAFFT-Net 구현 (인공지능심화 과제) (0) | 2022.12.05 |
|---|---|
| DeepRFTNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
| MobileNetV3 쉬운 논문 리뷰 및 Pytorch 구현 (0) | 2022.08.02 |
| MnasNet 쉬운 논문 리뷰 (0) | 2022.08.01 |
| ShuffleNet 쉬운 논문 리뷰/구현 (0) | 2022.07.20 |




댓글