MnasNet
[Reference]
논문 링크: MnasNet: Platform-Aware Neural Architecture Search for Mobile
github: https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet
- 2019년 4월 (Arxiv)
- Google Inc.
- Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le
blog: https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=za_bc&logNo=221570652712
[TODOS]
- Proximal Policy Optimization에 대한 내용 정리
[Question]
- Reward에서
(본문에선 a, b로 작성)이 고정되어있는데, 이게 진짜 Pareto Optimal이라고 할 수 있는가?
Abstract & Introduce
Automated Mobile Neural Architecture Search: 모바일에서 사용가능한 구조를 자동으로 찾는 것 이때, Accuracy 뿐만아니라, Latency도 같이 고려함
Abstract및 Introduce는 말그대로 요약이며, 이는 설명파트에서 더 풀어서 쓸 예정
최신의 CNN 모델들은 더 깊어지고 크기가 커짐
- 속도 감소, Computational Cost 증가
- 이로인해, Mobile 및 Embedded Board와 같은 제한된 자원의 Platform에서 사용 어려움
- 이를 위해 Depthwise Convolution, Group Convolution등을 통해 CNN 개선 중
- 하지만 Resource가 제한된 모델을 설계하는 것은 어려움
효율적인 모델을 찾기위해 자동화된 Neural Architecture Search 접근법 제시
Accuracy와 Latency 의 적절한 타협점을 갖는 모델을 찾는 Mobile NAS 제시
- Accurcy와 Latency를 모두 목표로 한다고 하여 Multi-Objective Neural Architecture Search Approach라 함
Search Space와 Flexibility 사이의 적절한 균형을 위해, Network 전체에 계층 다양성을 장려하는 새로운 Factorized hierarchical search space 제안
- 이전에는 적은 종류의 cell을 반복적으로 쌓아 Network를 만들었기에, 검색과정이 다양하지 못했음
- 다양성은 좋은 모델을 만들때에 중요한 요소
이때, FLOPS가 MACs는 Latency의 감소를 대표하는 값이 아님
FLOPS가 높은것에 비해 latency 감소가 적을 수 있고, MACs와 Latency가 정비례하지 않음
- FLOPS: Floating point OPerations per Second
- MACs: the number of Multiply-Accumulates
따라서 이 논문에선 실제 Latency를 구하기위해 Real-world에서 구동한 정보 활용 (Pixel1에서 구동한 Latency를 측정하여 사용)
용어 정리
SERatio(Reduction Ratio): SEBlock의 Excitation Operation에서 Fully Connected Layer를 얼마나 압축할건지 정하는 비율 자세한 내용은 링크의 3-1 참고
Sub Space Search: 하나의 Layer를 구성하는 경우의 수
- Convolution의 종류 3가지, Kernel 크기 종류 3가지를 가지고 하나의 Layer를 구성한다고 했을때 3*3의 Sub space search를 가짐
Pareto Optimal: (논문에선) Latency와 Accuracy의 trade-off 관계에서 파레토 개선이 불가능한 상태
- 즉, 최적의 타협점
Proximal Policy Optimization: 링크 참고
NasNet: RNN기반 Controller가 적당히 괜찮은 모델을 Sampling하고, 그 모델로 데이터를 학습하였을때 나온 값을 Reward로 하여 되먹여가며 Reinforcement Learning 진행하여 최종적으로 더 좋은 Architecture을 뽑아낼 수 있도록함
- 이때까진 Accuracy에만 초점을 맞춰서 연구를 진행함
- 이 논문에서 원하는건 Accuracy와 Latency 모두 잡는 것
설명
1. Mobile Neural Architecture Search
1-1. Factorized Hierarchical Search Space
몇개의 cell을 반복적으로 쌓는 구조는 다양성에 한계와, 높은 Latency를 보임
따라서 이 논문에선 기존과 다르게 진행함
CNN모델을 Unique block으로 제작
Operation과 Connection을 각각 찾아 다른 Block에서 다른 Architecture를 가질수 있도록 함
- 이를 통해 다양성을 증가시키고, 다양성 증가를 통해 Computational Cost 감소 및 성능 향상
- 예를들어, Depthwise Convolution을 진행할 때, Kernel이 커지면 Receptive Field는 커지겠지만, Output Channels의 개수는 줄어야 Cost 감소
- 다양성을 통해 이를 조율하여, Accuracy와 Latency의 Trade-off를 조절하여 최적의 지점을 구함
Search Space의 Baseline 구조는 다음과 같음
CNN 모델을 미리 정의된 Block들을 연결하여 만들고 (Standard Conv Block, Depthwise Conv Block, ... 등을 결합하여 Network 제작)
Input resolution을 점진적으로 줄이고, Filter size를 키움
이때 각각의 Block은 정해져있는 Layer 목록들을 가지며, Block별로 Operation과 Connection들이 결정됨
- 모든 가능성을 열어놓고 Sub Space를 지정한 것이 아닌, 논문 작성자들의 노하우를 바탕으로 Sub Space 영역을 한정함
이때 Sub search space는 다음과같이 구성되어있음
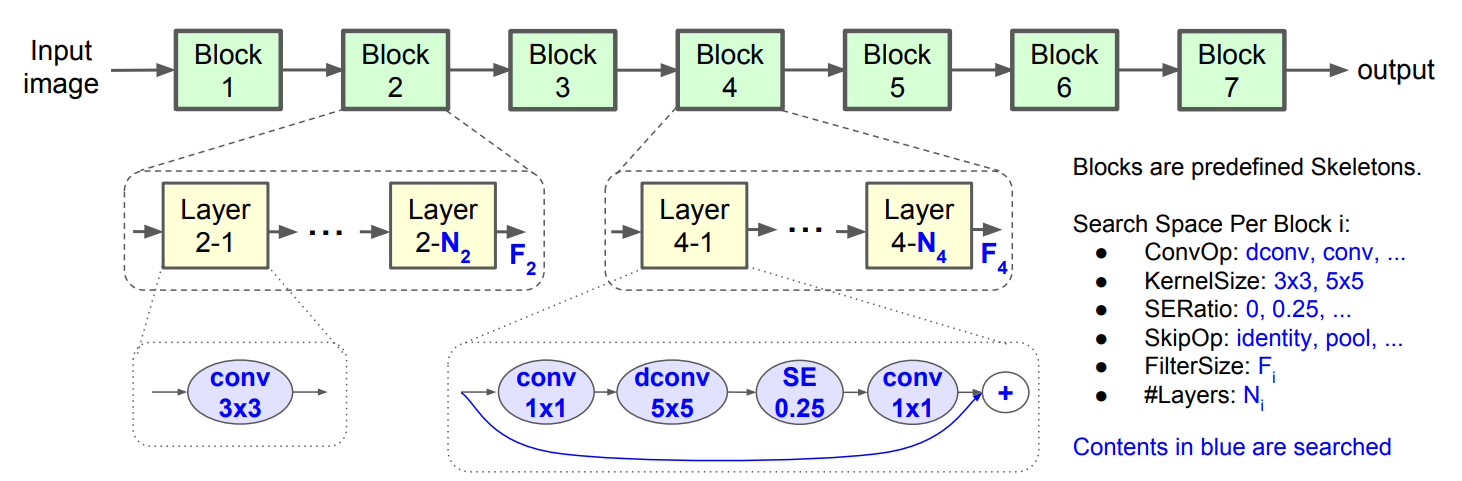
- 위의 그림에서 Layer4의 경우에는 Inverted Bottleneck Convolution Operation을 진행한 뒤
- Skip Connection을
번 반복하여 하나의 Block 설계
- ConvOp: Standard / Depthwise / Mobile inverted bottleneck Convolution
- Kernel Size: 3x3, 5x5
- SERatio (Squeeze-and-Excitation Ratio): 0, 0.25
- SkipOp: Pooling, Identity Residual, No-skip
- Output filter size:
- Number of layers per block:
// 레이어가 얼마나 반복될 것인지 결정
이를통해 layer의 다양성과 전체 Search space Size간의 Balance를 잘 맞출 수 있음
Total Search Space
- Network를
개의 Block으로 구성 - 각 Block마다
의 Sub-Search Space가 있고 - 한개의 Block 마다
개의 Layer가 있다하면 - Per-layer Approach의 Total Search Sapce size는
- Network를
1-2. Search Algorithm
Reinforcement Learning(RL, 강화학습)을 통해 Multi-object Search Problem을 해결함
- Multi-object: Accuracy & Latency
- 편리하고 Reward가 Customizing하기 편한 Reinforce Learning 방식 사용
- CNN Model이 token들의 list에 mapping함
- Token들은 매개변수
를 기반으로 강화 학습한 Agent의 Action 의 Sequence에 의해 결정됨
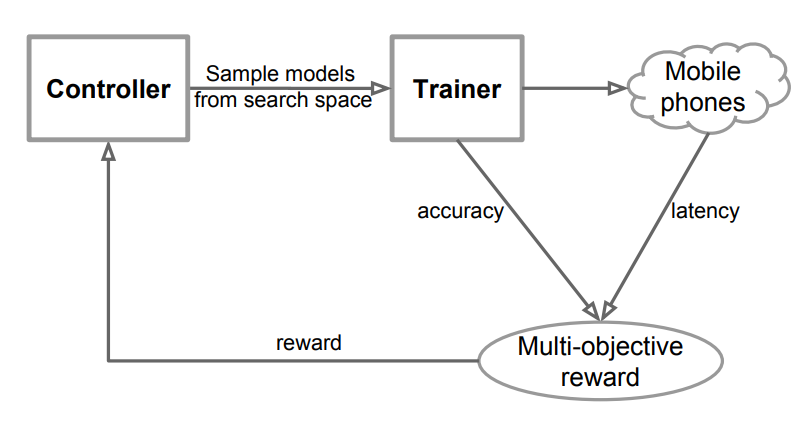
위의 구조로, 다음의 Sample-eval-update Loop를 통해 학습 진행
Controller가 Current Parameter
를 사용하여 RNN의 Softmax logits를 기반으로 Token의 Sequence를 예측하여 Model의 묶음들을 Sampling 각각 샘플링된 모델 m에 대하여 Train을 진행시켜 정확도 ACC(m)를 구하고, Real Phone에서 Inference를 진행시켜 지연 시간 LAT(m)을 얻음
이후에 다음의 수식을 통해 Reward R(m)을 계산
단순히 Latency가 T보다 작을때 중에서 가장 높은 ACC를 보이는 모델을 고르면 될수도 있지만 이것만으로는 Pareto Optimal을 달성할 수 없음Model: Action
를 통해 생성된 모델 Accuracy:
Inference latency:
Target latency:
// 한계 시간 T이내의 latency로 최고의 정확도를 만들어 내도록 : if LAT(m) <= T: # Latency가 T보다 작을 때 Reward의 w값 설정 w = a else: # Latency가 T보다 클 때 Reward의 w값 설정 w = b (w <= 0)ACC가 커지면 reward가 커지고, w는 음수이기 때문에, LAT가 커지면 reward가 작아지고각각의 Step의 마지막에서 Reward를 최대화하는 방향으로 Controller의
를 Proximal Policy Optimization을 사용하여 Update 최대 Step수 또는 최적의
에 도달할 때 까지 Loop 반복
2. Experiment
2-1. Experimental Setup
효율적이지 못하단걸 알지만 NASNet과 동일한 RNN Controller를 사용
ImageNet training set을 사용했고, 5 epochs의 적은 training step을 가짐
- 50K images를 Random하게 선택하여 Validation Set으로 사용
COCO dataset을 이용하였음
- trainval35k를 통해 학습
- dev2017로 Evaluate
Real-world latency를 측정하기위해, Pixel 1 사용
최종적으로, Controller가 8K의 최적화된 Models Architecture를 탐색하였고,
이중 15개의 Top-performing models ImageNet(Image classification data set)을 학습하는데 사용
- 이때 RMSProp optimizer의
로 설정 - Batch norm은 매 Convolution layer 뒤에 붙음 이떄,
- Dropout rate = 0.2
- Learning rate는 처음 5step 동안 0부터 0.256으로 향상되었고, 이후 2.4 epochs 마다 0.97 decay 되었음
- 이때 RMSProp optimizer의
1개의 model은 COCO(Object detection dataset)를 학습하는데 사용
Reward 함수 조건 설정
Target latency
로 잡아, MobileNetV2와 유사하게 잡았음 1-2 파트의
의 a, b를 각각 -0.07로 설정 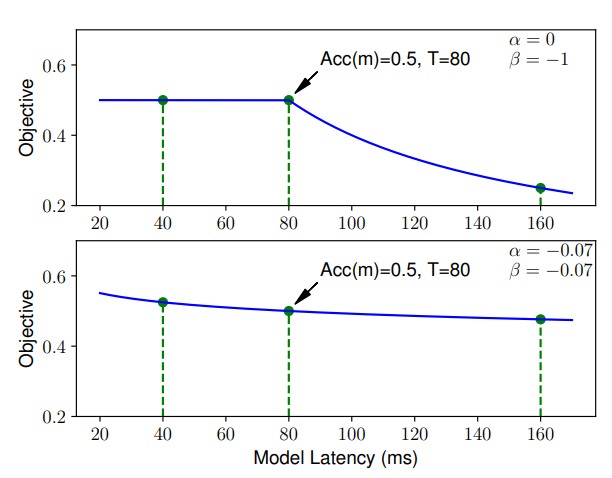
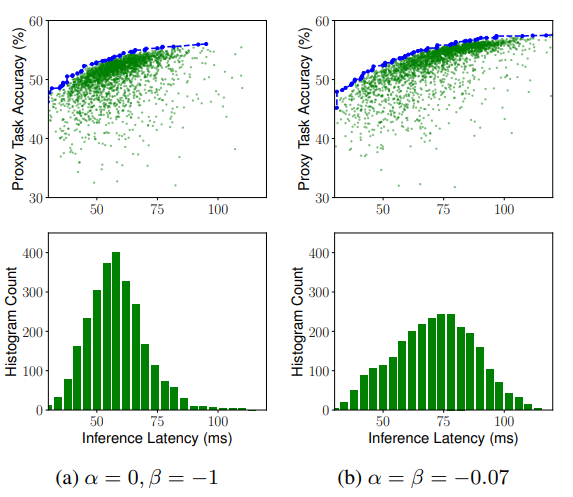
(a, b) = (0, -1)의 경우: Hard constraint (강한 제약조건)
Latency Penalty를 줄이기 위해, 제약시간 T안에서만 모델을 찾음 / 제약시간안에선 정확도에 강하게 Targeting함
- 지연시간이 T보다 작을 땐 Latency에 대한 Penalty를 주지 않음
- 지연시간이 T보다 클 땐 Latency에 대한 Penalty를 크게 줌. Latency가 커질수록 Reward 폭풍 감소
(a, b) = (-0.7, -0.7)의 경우: Soft constraint (약한 제약조건)
Latency Penalty가 적기때문에, 더 넓은 Latency range에서 유연하게 모델을 찾음
- 경험적으로 설정
2-2. Results
- ImageNet Classification 결과
다른 모델들 보다 적은 Latency로 더 뛰어난 Accuracy를 보임
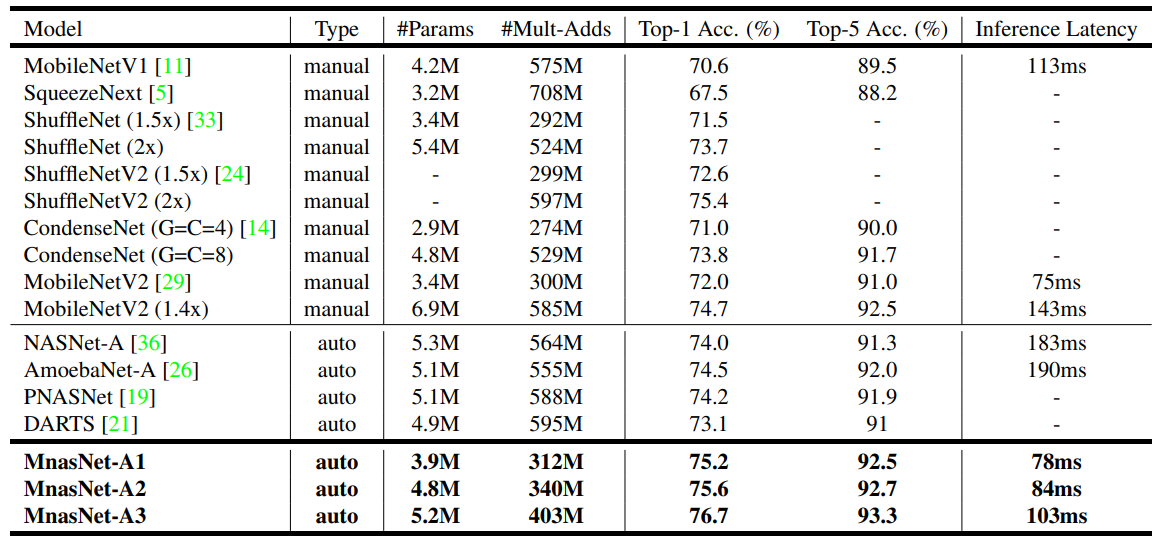
MobileNetV2와 비교하여, 유사한 Latency로 더 높은 정확도를 가지며, Latency를 임의로 조절하여 정확도와의 Trade-off를 조절 가능
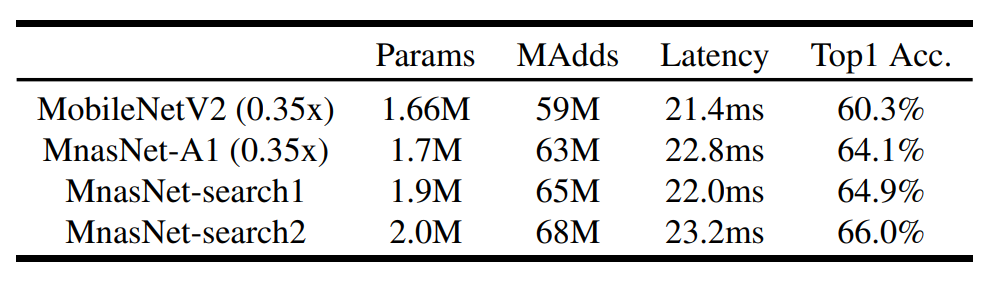
- COCO Object Detection 결과
적은 Latency로 높은 mAP 달성
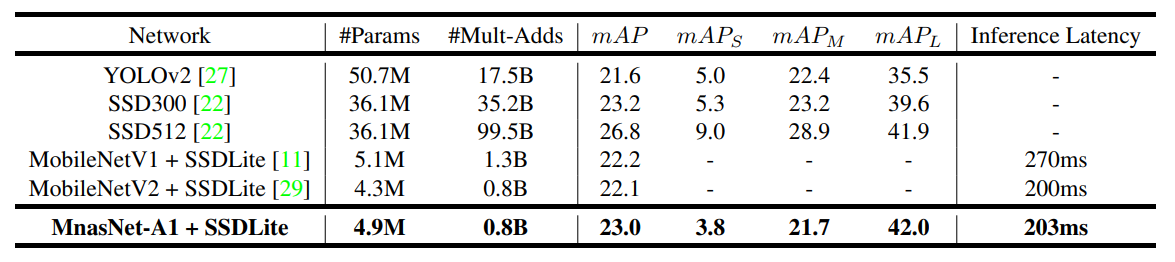
- 모델 제작 결과
- MBConv: Mobile inverted bottleneck conv
- DWConv: depthwise conv
- BN: Batch Normalize
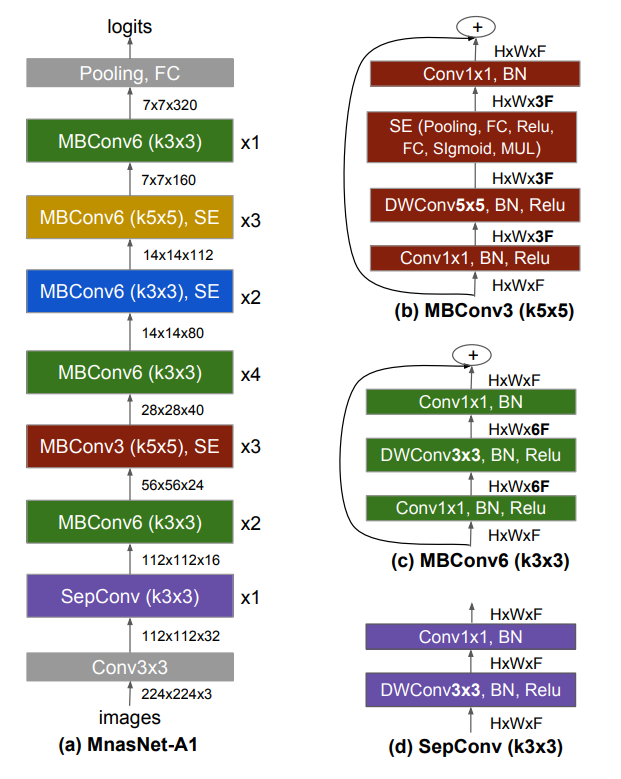
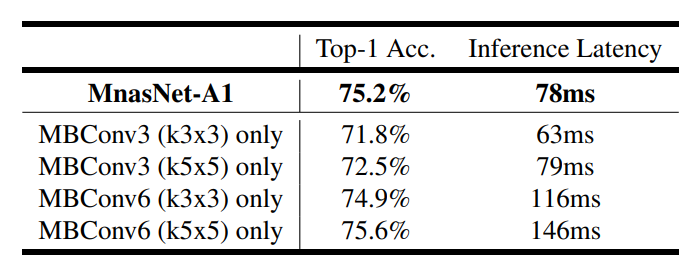
block마다 제작기 다른 Convolution Operation을 수행 (Kernel size = 3x3 or 5x5)
- 본래 5x5 Convolution Operation은 3x3 Convolution 2개와 동일한 Receptive Field를 가지며, 연산량이 더 많은것으로 알고 사용하지 않았으나
- 실제로 Output Channel의 수가 일정 수 이상이면 3x3 2개보다 5x5 Convolution 연산이 연산량이 더 적음
이처럼 다양한 Filter의 size의 배치와 Reduction Ratio의 설정이 좋은 성능으로 연결됨
Kernel의 size를 고정시키고 모델을 제작하면, 정확도가 떨어지거나, Latency가 상승하는것을 확인할 수 있음
'Computer Vision' 카테고리의 다른 글
| NAFNet 쉬운 논문 리뷰 (0) | 2022.11.27 |
|---|---|
| MobileNetV3 쉬운 논문 리뷰 및 Pytorch 구현 (0) | 2022.08.02 |
| ShuffleNet 쉬운 논문 리뷰/구현 (0) | 2022.07.20 |
| Squeeze-Excitation Network 쉬운 논문 리뷰/구현 (0) | 2022.07.19 |
| MobileNet V2 쉬운 논문 리뷰/구현 (1) | 2022.07.07 |




댓글